Azure Text to Speech: Voice Revolutionizing Your Tech Projects

Integrating Azure's Lifelike TTS into Your Applications
Azure's Text-to-Speech (TTS) service exemplifies the cutting edge of voice synthesis, poised at the intersection of AI innovation and practical utility. Developers and engineers working with text to speech APIs will find Azure's offerings particularly compelling, as they encompass a suite of lifelike voices enriched by neural TTS technology. Microsoft has engineered these voices to be as versatile and customizable as they are realistic, thereby setting new standards in the industry for what digital speech can and should sound like. Whether you are looking to develop applications in education, create chatbots for customer service, or integrate responsive narration in multimedia, Azure's TTS technology ensures that your projects will resonate with clear, natural voice output.
Furthermore, Microsoft's commitment to making this technology accessible is evident in its flexible pricing model and the security that underpins its TTS API – considerations of paramount importance for professionals in the highly dynamic fields of Python, Java, and Javascript development. By incorporating Azure's TTS into your digital environments, you unlock the potential to enrich user experience significantly. With each implementation, you contribute to setting a new precedent in the digital domain, where interfaces are not just heard but genuinely listened to and interacted with, thereby redefining user engagement in the era of neural TTS tech.
| Topics | Discussions |
|---|---|
| Azure Text to Speech Overview | An overview of Microsoft Azure's Text to Speech service, showcasing innovative AI capabilities for lifelike speech synthesis. |
| Empowering Applications with Azure TTS | How Azure's TTS technology enables developers to enhance their applications with natural-sounding and customizable voices. |
| Practical Implementation of TTS in Tech | Discussion on integrating TTS into technological solutions and the practical benefits of using Azure's TTS services. |
| Common Questions Re: Azure TTS | Answers to common questions about neural TTS technology, highlighting the use of neural networks and the advancements over standard TTS. |
Azure Text to Speech Overview
As we journey through the intricate world of Azure's Text to Speech technology, it becomes imperative to understand the key terms foundational to this advanced AI domain. For researchers and software engineers, a grasp of these terms not only enhances comprehension but also empowers application development and research within the realms of Python, Java, and Javascript. With neural TTS technology at the forefront, this glossary will serve as your beacon through the transformative landscape of Azure's voice synthesis capabilities.
Text-to-Speech (TTS): The technology that converts written text into spoken words or audio speech.
Neural TTS: Advanced TTS systems that use neural network algorithms to produce more natural and human-like speech.
API (Application Programming Interface): An interface allowing software applications to communicate with each other, essential for integrating TTS functions.
Machine Learning (ML): A form of AI that enables software to predict outcomes and learn from data without being explicitly programmed to perform specific tasks.
Deep Learning: A subset of ML based on artificial neural networks designed to model complex patterns and data.
Synthetic Voice: An artificial voice generated by TTS technology, often customizable to fit various use cases and preferences.
Voice Synthesis: The process by which TTS technology creates artificial speech.
Cloud-based TTS: TTS services that are hosted on cloud platforms, allowing for scalable and accessible voice generation capabilities.
Customization: The ability to personalize aspects of TTS, such as voice type, language, accent, pitch, and speed.
Security in TTS: Measures and protocols in place to protect voice data and ensure the privacy and safety of TTS applications.
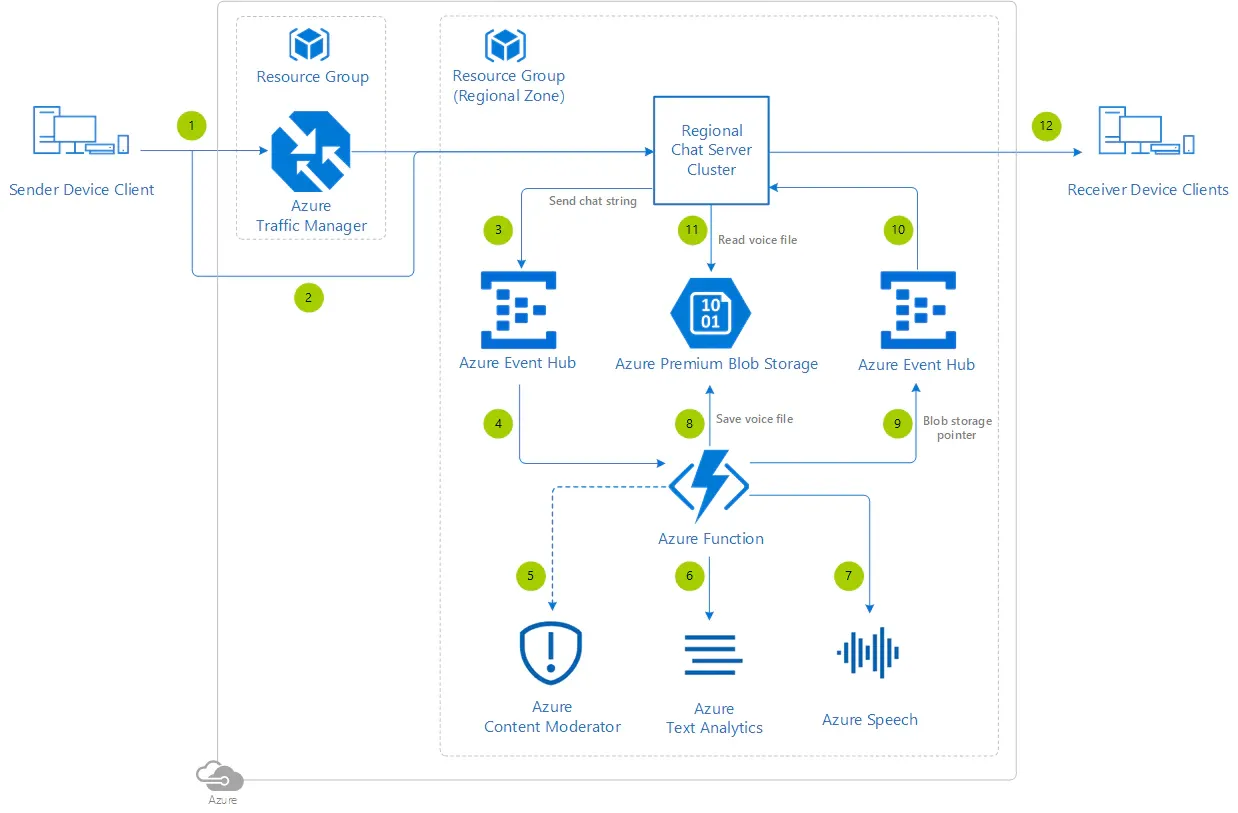
Empowering Applications with Azure TTS
Microsoft Azure's Text to Speech service offers a high degree of flexibility, inviting users to experience its capabilities through a generous free trial or through a pay-as-you-go account structure. Esteemed for its access and ease of use, the service can be explored through Azure's TTS page, where interested developers can initiate their journeys in integrating sophisticated speech capabilities within their applications. Efficiency and accessibility are the keystones of this service, designed to facilitate the seamless integration of lifelike speech that caters to a diverse range of digital platforms.
By focusing on enriching brand identity through customizable and natural-sounding voices, Azure TTS empowers businesses to convey their unique characters audibly. The variety of voices available, complete with diverse speaking styles and emotional tones, underscores the service's adaptability for any use case—from engaging audiobook narrations to responsive customer service interfaces. This versatility is particularly advantageous for software engineers and developers specializing in Python, Java, and Javascript, providing them tools to revolutionize their projects.
Azure's highlighted features underscore a firm commitment to providing a secure and scalable text-to-speech solution. Developers vested in crafting advanced cloud-based applications will find the information on the Azure TTS resource page invaluable, as it ensures a blend of security measures, competitive pricing, and ample resources designed to enable a swift start with the technology. While specific authorship or affiliations with universities or research groups regarding this Azure TTS data is not detailed, the broad outreach of the page suggests a comprehensive approach aimed at a wide audience of tech professionals.
Practical Implementation of TTS in Tech
The transition from textual to spoken content has been made effortless with Azure's Text to Speech service, designed to facilitate developers in bringing TTS capabilities to a vast array of applications. From mobile interfaces with voice-guided navigation to assistive reading technologies, Azure TTS plays an invaluable role with its state-of-the-art synthesis that boasts natural and customizable voice outputs. This service becomes particularly relevant for those in the scientific and engineering fields, offering a tool that not only simplifies the development process but also enhances the end-user experience.
Incorporating Azure's TTS into technological solutions is characterized by its ease, empowering creators to provide interactive and engaging systems that respond and communicate with clarity and human-like articulation. The service's modular and developer-friendly nature means that integration into existing projects or new builds is straightforward, requiring minimal setup. The APIs provided by Azure encourage innovation, paving the way for new functionalities that were once challenging to implement.
TTS technology has positioned itself as a keystone in tech development, especially as industries converge towards more personalized and adaptive digital experiences. Azure's offering ensures that this transition not only meets the current standards but sets new benchmarks for what TTS can achieve within the tech ecosystem. By integrating Azure TTS, various tech-driven sectors can enhance their operational efficiency, reduce time-to-market for new voice-enabled features, and most importantly, establish more profound connections with their audiences.
For current and accurate information, consult the official documentation provided by Azure, which includes detailed guides and updated code samples relevant to their Text to Speech service. The documentation is a valuable resource for developers and includes explanations, tutorials, and examples on how to implement and use their TTS services within your applications.
Leveraging Unreal Speech for Diverse Domains
Unreal Speech's text-to-speech synthesis API boasts of slashing costs by up to 90%, making advanced TTS technology more accessible than ever before. For academic researchers, such affordability opens doors to integrating natural-sounding speech into their study materials, experiments, and educational tools, without depleting precious funding. The power of TTS to verbalize written content can enhance the comprehensibility of complex concepts and supports diverse learning styles within the academic community.
Software engineers can harness the Unreal Speech API to develop responsive, voice-interactive applications. Whether creating assistive technologies or engaging gaming experiences, the promise of reduced costs and high-quality output equates to more room for innovation and experimentation within budget constraints. The API's claim of high uptime and low latency ensures reliable integration into software products, essential for maintaining a smooth user experience.
For game developers, Unreal Speech provides an opportunity to populate virtual worlds with a multitude of realistic voices, elevating the storytelling aspect of gameplay. Educators, too, can capitalize on this tool to create immersive learning content, ensuring inclusivity for those with reading difficulties or preference for auditory learning. With the enterprise plan, even high-volume projects become feasible, granting access to extensive characters and hours of speech that might otherwise be prohibitive. The commitment to upcoming multilingual support further ensures expansion in global reach, crucial for creating content across different demographic groups.
Common Questions Re: Azure TTS
Understanding Neural TTS Implementation
Neural Text-to-Speech (TTS) technology, a key element of Azure's AI services, is a pioneering implementation that uses advanced neural network architectures to create speech that closely resembles human-like tonality and clarity. This sophisticated approach results in an engaging audio experience that is deeply resonant and contextually aware.
Comprehending Neural vs. Standard TTS
The distinction between neural and traditional standard TTS technologies lies in the adoption of machine learning models that enable a nuanced and dynamic range in voice synthesis. Unlike standard TTS, which often concatenates pre-recorded audio clips, Azure's neural TTS generates fluid, lifelike speech patterns that smoothly articulate the complexities of language.
Exploring TTS in Modern Technology
In the realm of modern technology, Azure's Text-to-Speech is not just a functional feature but a transformative force that drives interactive applications and next-gen digital solutions. It extends beyond reading scripts, enhancing user experiences with responsive, natural-sounding speech across various AI-driven platforms.