Deep Learning in TTS: Latest Techniques and Tools for Speech Synthesis

Unlocking the Secrets of Deep Learning in Text-to-Speech Systems
In the realm of speech synthesis software, deep learning stands as a revolutionary force, propelling TTS systems into realms of unprecedented realism and functionality. These cutting-edge systems are no longer confined to robotic monotones but now have the capability to convey the intricacies and inflections of human speech with remarkable fidelity. By harnessing the power of advanced neural networks, developers have made significant strides in creating software that can accurately mimic human speech patterns, enabling applications from AI tools for speech to more natural-sounding virtual assistants and chatbots.
With the advent of free TTS software for PC, the technology has become more accessible, fostering innovation in everything from online free unlimited TTS to high-quality, AI-powered voice cloning. This democratization of technology allows for rapid experimentation and deployment, furthering the research and development in speech synthesis. Meanwhile, Google's TTS technology and other online text-to-speech synthesis platforms continue to evolve, drawing on powerful algorithms to provide users with not just speech, but speech that emulates the cadence and emotion of authentic dialogue.
| Topics | Discussions |
|---|---|
| Exploring the Impact of Deep Learning on TTS | Delve into the transformative role of deep learning in enhancing current text-to-speech systems, focusing on neural network integration and AI's role in advancing speech synthesis technologies. |
| "A Deep Learning Approaches in Text-to-Speech System: A Systematic Review and Recent Research Perspective" | Gain an in-depth understanding of the systematic review that dissects recent deep learning methods in TTS, scrutinizes quality metrics, and offers a comparative analysis of global research efforts. |
| State-of-the-Art Trends in Speech Synthesis Software | Stay ahead of the curve with the latest trends and breakthroughs in speech synthesis software, influenced by deep learning for unmatched naturalness and accuracy. |
| Technical Quickstart: TTS Development with Programming Code Samples | Accelerate your technical prowess with practical code samples and tutorials that streamline the development process for creating sophisticated text-to-speech systems in various programming languages. |
| Leveraging Free TTS Tools for Enhanced Communication | Maximize communication efficiency by utilizing the finest free TTS tools available, unlocking high-quality, unlimited synthetic speech capabilities for diverse applications. |
| Common Questions Re: TTS Techniques and Tools | Addressing frequent inquiries about TTS techniques and tools, this section provides authoritative answers and clarifications to the most pressing questions in the field. |
Exploring the Impact of Deep Learning on TTS
Embark on a journey through the pivotal impact of deep learning on text-to-speech (TTS) technologies, where algorithms inspired by the human brain transform text into spoken word with astonishing naturalness. To navigate this landscape, it is essential to grasp the key terminologies that form the cornerstone of TTS advancements. We introduce a glossary designed to enrich your understanding and enhance the dialogue surrounding these evolving technologies.
| Term | Definition |
|---|---|
| Deep Learning (DL) | A subset of machine learning where artificial neural networks, algorithms inspired by the human brain, learn from large amounts of data. |
| Text-to-Speech (TTS) | The process of converting text into spoken voice output, typically using software. |
| Neural Networks | A series of algorithms that attempt to recognize underlying relationships in a set of data through a process that mimics the way the human brain operates. |
| Speech Synthesis | The artificial production of human speech, often implemented in TTS systems. |
| Accuracy | In TTS systems, the closeness of the generated speech to human-like pronunciation and intonation. |
| Recognition Rate | The ability of a TTS system to correctly interpret text and represent it in synthesized speech accurately. |
| Quality Metrics | Standards or measurements used to evaluate the performance of TTS systems, including naturalness, intelligibility, and fluency. |
| TTS Score | A quantitative value representing the quality of a synthesized speech system, often judged by listeners or objective measurements. |
| AI-Powered Voice Cloning | The creation of a digital replica of a human's voice pattern using AI methods, specifically within the context of TTS. |
| Chatbots | Computer software designed to simulate conversation with human users, often utilizing TTS technologies to vocalize responses. |
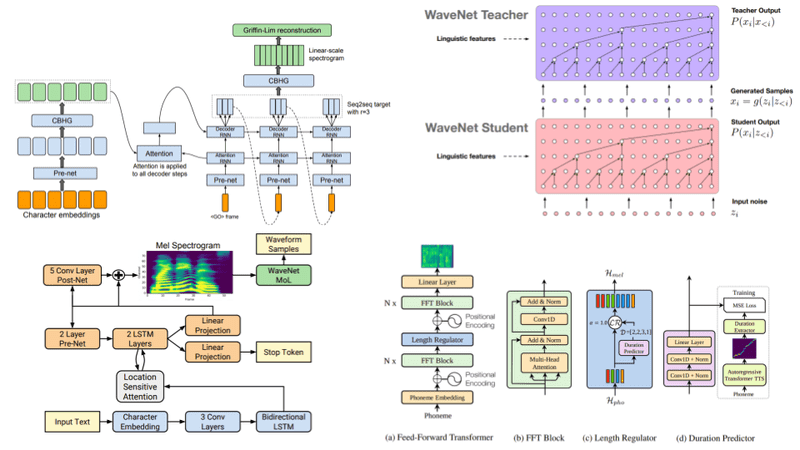
"A Deep Learning Approaches in Text-to-Speech System: A Systematic Review and Recent Research Perspective"
Published in the esteemed "Multimedia Tools and Applications," the research paper by Yogesh Kumar, Apeksha Koul, and Chamkaur Singh delivers a critical analysis of deep learning (DL) methodologies within TTS frameworks. Dated September 29, 2022, it delves into the DL strategies that have reshaped TTS, suggesting that neural networks are central to the current and future landscape of spoken language technology. The authors, whose affiliations range from academic institutions to potentially private research groups, systematically gather and present data that underscores the evolution from traditional synthesis to AI-driven vocalization.
The paper critically explores key trends such as neural TTS, an advanced subset of TTS that integrates DL to create highly accurate and natural voices. It addresses implementations in interactive applications, highlighting the enhancement of user experiences via conversational agents like chatbots. Furthermore, the analysis extends to how these DL processes are revolutionizing systems to offer refined speech quality across diverse languages and dialects.
A focal point of the study is the evaluation of TTS systems based on quality metrics. Recognition rate, accuracy, and collective TTS scores are dissected to compare and contrast the performance of multiple TTS systems. These metrics underscore the strides made in Indian and non-Indian language systems, reflecting the DL techniques that embody the crux of these improvements. Such insights are invaluable for those engaged in designing TTS solutions that are both innovative and culturally nuanced.
Measuring Success: Quality Metrics in TTS Evaluation
To truly gauge the progression and efficacy of TTS systems, the paper advocates for a standardized approach in using quality metrics. Metrics like recognition rate, which measures a system's ability to understand and replicate text with precision, are critical benchmarks. Accuracy is another touchstone, signaling the system's capability to vocally replicate the intended content without distortion. By systematically reviewing different systems' TTS scores—a quantitative indicator of quality—researchers can effectively strategize future enhancements.
Global Challenges: Insights from Indian and Non-Indian TTS Research
The review provides a cross-cultural view of TTS technology, addressing the challenges faced in creating systems that cater to Indian and non-Indian languages. Each linguistic landscape presents its unique deep learning obstacles and opportunities. Whether through refining phonetic accuracy or overcoming dialect diversity, the paper emphasizes the importance of specialized research and development endeavors to make TTS technology inclusive and globally adaptable.
State-of-the-Art Trends in Speech Synthesis Software
The fast-paced world of speech synthesis is ever-evolving, with deep learning (DL) continually driving advancements in text-to-speech (TTS) systems. State-of-the-art trends in the industry are setting new standards for what TTS can achieve, from creating extraordinarily lifelike voices to facilitating more natural human-computer interaction. Breakthroughs in AI tools for speech are streamlining processes across various sectors, including education, health care, and customer service, proving the versatility and critical necessity of these developments.
Advances in speech synthesis are not just about voice quality but also about the utility and flexibility of these tools. Software updates now often include multi-lingual support, adaptive learning abilities to enhance voice modulation, and the backing of robust frameworks capable of handling vast datasets for nuanced voice generation. As free text-to-speech software for PC becomes sophisticated, more users can access high-quality voice generation for personal and professional uses, signaling a democratization of speech technology tools.
Within the TTS field, one standout trend is the development of open-source projects that invite collaboration and innovation from developers worldwide. By sharing advancements and build-ups, the community collectively pushes the boundaries of what synthetic speech can emulate. Combined with the explosion of cloud-based TTS services, these advancements promise a future where access to high-quality synthetic vocalization is easy, inexpensive, and nearly indistinguishable from human speech.
Technical Quickstart: TTS Development with Programming Code Samples
Python Snippets for Text to Speech Synthesis Online Free
First, install the gTTS library using pip:
pip install gTTS
After installation, you can write a script to convert text into speech. Here's a simple Python code snippet:
from gtts import gTTS
import os
This code generates an MP3 file from the text "Hello World!" using an English-speaking voice. You can play this MP3 file on any compatible audio software.
Java and JavaScript Techniques for Text to Speech Synthesis
For Java enthusiasts, TTS can be integrated using the FreeTTS library, a wrapper for the Festival TTS engine. However, to keep our quickstart guide concise and up to date, we'll focus on the more common scenario for TTS development: the Web, where JavaScript is the language of choice.
Using the Web Speech API, which is supported in most modern browsers, you can easily implement TTS with the following JavaScript code:
const axios = require('axios');
const fs = require('fs');
const headers = {
'Authorization': 'Bearer YOUR_API_KEY',
};
const data = {
'Text': '<YOUR_TEXT>', // Up to 1,000 characters
'VoiceId': '<VOICE_ID>', // Scarlett, Dan, Liv, Will, Amy
'Bitrate': '192k', // 320k, 256k, 192k, ...
'Speed': '0', // -1.0 to 1.0
'Pitch': '1', // 0.5 to 1.5
'Codec': 'libmp3lame', // libmp3lame or pcm_mulaw
};
axios({
method: 'post',
url: 'https://api.v6.unrealspeech.com/stream',
headers: headers,
data: data,
responseType: 'stream'
}).then(function (response) {
response.data.pipe(fs.createWriteStream('audio.mp3'))
});This JavaScript snippet creates an instance of the SpeechSynthesisUtterance object with the text you want to speak and then passes it to the speechSynthesis system of the browser, effectively turning text into audible speech.
Leveraging Free TTS Tools for Enhanced Communication
Unreal Speech is carving out a space as a cost-effective solution in the TTS field, with its API offering up to a 90% slash in costs compared to competitors like Eleven Labs and Play.ht, and up to double the affordability against giants such as Amazon, Microsoft, and Google. Their enterprise plan, including 625M characters for about $4999 a month, positions them as an attractive option for high-volume processing needs - boasting a latency of 0.3 seconds, impressive 99.9% uptime, and capabilities of handling thousands of pages per hour.
From academic research to software engineering, and from game development to educational tools, Unreal Speech's API serves a broad spectrum of users looking for efficient and economical TTS options. With an enterprise-level plan suitable for extensive use, this platform could be especially beneficial for those who need to synthesize large volumes of text into speech regularly. Its scalable pricing model becomes more cost-effective with increased usage, making it ideal for initiatives that might otherwise be curtailed by budget constraints.
For developers, the platform is straightforward to integrate, offering Python, Node.js, and React Native code samples to get started quickly. Whether you are developing real-time apps that require instantaneous audio playback or creating lengthy audio for content consumption, Unreal Speech provides the tools to generate high-quality TTS at impressive speeds. And with the anticipated addition of multilingual voice support, its applications are set only to expand further, providing valuable assets to a diverse range of industries.
Common Questions Re: TTS Techniques and Tools
How Can Speech Synthesis Software Improve User Experience?
Speech synthesis software can significantly enhance user experience by providing natural-sounding voice output. These tools enable more human-like interaction with technology, making it accessible and user-friendly.
What Sets Apart Speech Synthesis from Traditional TTS Methods?
Speech synthesis typically involves advanced algorithms and deep learning to generate speech that mimics human intonation and emotion, whereas traditional TTS methods may rely on more basic concatenation of recorded speech sounds.
How Does the TTS Algorithm Enhance Speech Clarity and Naturalness?
A TTS algorithm enhances speech clarity and naturalness by using machine learning to understand context and apply appropriate inflections, thereby producing more intuitive and seamless synthetic speech.