Exploring Unreal Speech's TTS API: Pioneering Neural Text-to-Speech Synthesis
The Dawn of Enhanced Digital Audio: Unreal Speech's TTS API Revolution
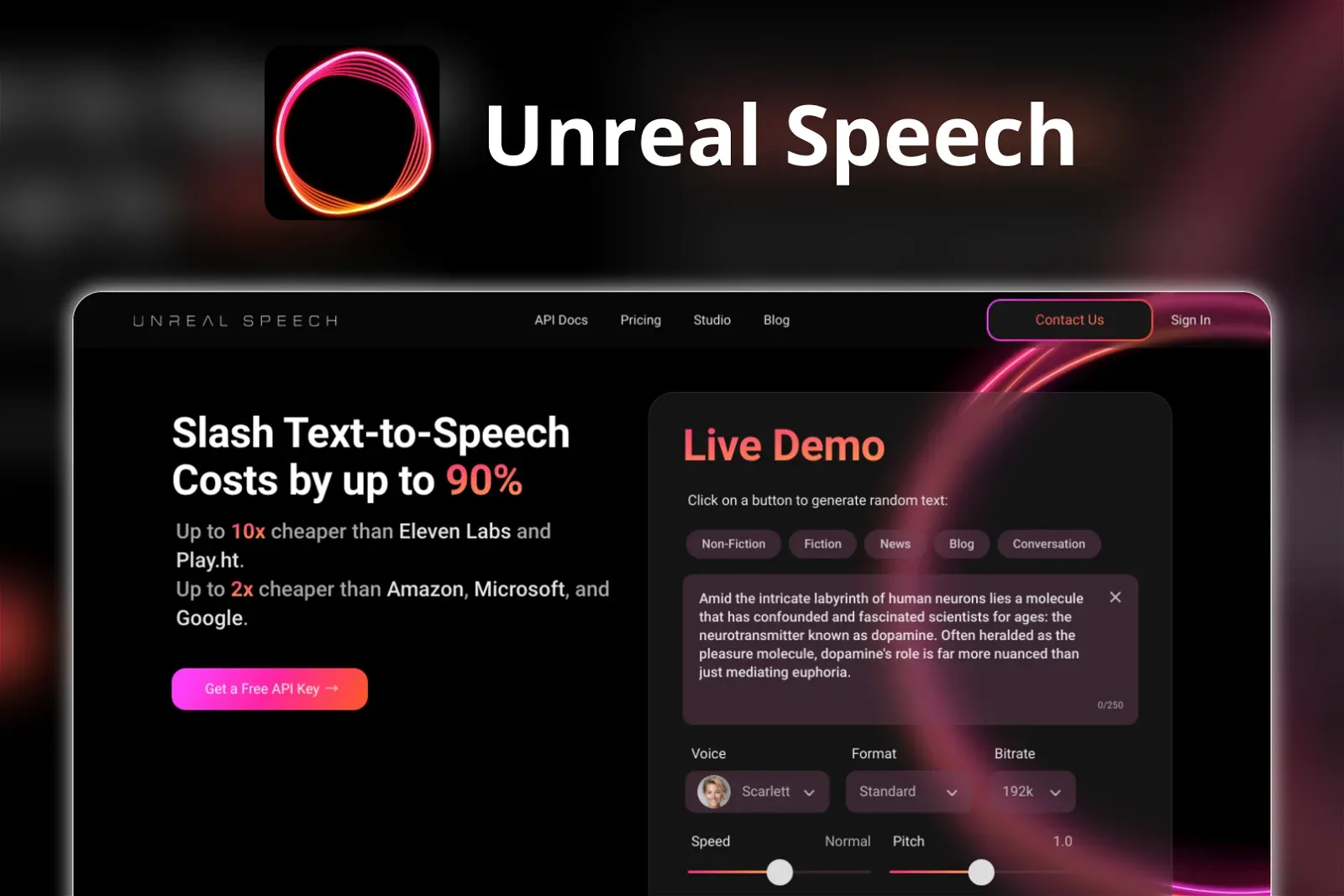
In 2023, Unreal Speech's TTS API emerged as a defining force in the digital audio sphere, marking a new chapter in the synthesis of speech technology. Addressing the most pressing questions surrounding this innovation, we uncover the API's ability to convert text to lifelike speech, enhancing interactive capabilities while maintaining a keen eye on user accessibility. This groundbreaking tool offers not only a new level of auditory experience but also a shift towards more intuitive and engaging human-computer interactions. As audio becomes more prevalent in our digital navigation, the Unreal Speech TTS API is at the forefront, providing developers with the means to evolve alongside the AI-driven landscape, ensuring that their creations are as vocal as they are visionary.
The significance of Unreal Speech's API goes beyond technical marvel; it is reshaping the way educators, developers, and content creators approach audio communication. The API's advanced neural network algorithms allow for the emulation of human nuances in speech, presenting opportunities to craft more natural and personalized voice experiences. Its user-friendly design, coupled with a cost-effective strategy, positions Unreal Speech as an accessible option for professionals striving to integrate robust TTS technology into their work. Through its enhanced speech synthesis capabilities, the TTS API from Unreal Speech stands as an accommodating bridge between the users' auditory demands and the infinite possibilities of machine learning-enhanced speech.
| Topics | Discussions |
|---|---|
| Unveiling Unreal Speech's TTS API | An introduction to the cutting-edge TTS API released by Unreal Speech, showcasing its potential to revolutionize speech synthesis. |
| Common Questions Re: Neural TTS Technology | Frequently asked questions about TTS technology, with a particular emphasis on its neural synthesis aspects and the differences from standard TTS systems. |
Unveiling Unreal Speech's TTS API
The Text-to-Speech (TTS) API brought forth by Unreal Speech represents a significant milestone in audio technology, promising to enhance not only the ease of accessibility but the very nature of user engagement across digital domains. For university research scientists and software engineers navigating the intersection of AI, machine learning, and auditory development, understanding the nuances of this tool is crucial. Here is a glossary of terms that will anchor you as you immerse yourself in the possibilities unfolded by this TTS API.
TTS (Text-to-Speech): A technology that converts written text into spoken audio, enabling applications and devices to communicate with users through voice.
API (Application Programming Interface): Programming rules that allow different software or applications to communicate, enabling the integration of complex TTS functions with ease.
Neural Network: An AI model designed to simulate the way the human brain analyzes and processes information.
Deep Learning: A subset of machine learning involving algorithms that identify patterns in large datasets, heavily used in creating realistic synthetic voices.
Machine Learning: A field within AI that gives computer systems the ability to learn and improve from experience without being explicitly programmed.
Synthesis: In the context of TTS, the process where the API converts text into speech.
Speech Synthesis: The artificial production of human speech by computer systems or software.
User Engagement: The extent to which users interact with a system, which can be significantly improved with the human-like voices provided by TTS tech.
Digital Accessibility: Ensuring digital content is easily navigable and comprehensible to all users, including those with disabilities, through technologies like TTS.
Operational Efficiency: The capacity of organizations or systems to maximize output from given inputs, which TTS technology can enhance by streamlining communication processes.

TTS API in Practice: Industry Applications
Unreal Speech's TTS API brings a disruptive innovation to text-to-speech technology, offering substantial cost reductions that democratize the field. Academic researchers can now access high-quality TTS technology without hefty investments, enabling a wider scope for experimentation and study. The API's claim of slashing speech synthesis costs by up to 90% translates into tangible savings, easing the financial burden on research projects.
For software engineers, implementing Unreal Speech's API means more resources to allocate towards other aspects of development, such as user interface design and functionality improvements. The promise of performance exceeding that of established competitors like Amazon Polly at lower costs is a game-changer, offering efficient solutions for projects requiring voice capabilities. Additionally, the per-word timestamp feature provides a meticulous level of detail beneficial for developing interactive media applications where precise voice-to-text alignment is crucial.
Game developers searching for realistic voiceovers will find Unreal Speech's affordable enterprise plans particularly beneficial, as they provide an extensive range of characters per month at predictable costs. Educators focused on creating accessible content will appreciate the potential for streamlined generation of audio books and instructional materials. With the API's volume discounts and the feature-rich enterprise plan, Unreal Speech fosters a creative environment for voice synthesis, proving advantageous across digital industries looking to enhance accessibility and cater to diverse user needs.
Common Questions Re: Neural TTS Technology
Unraveling Neural Speech Synthesis
Neural speech synthesis uses deep learning to produce human-like speech from text. It involves training neural networks on large datasets to understand the aspect of human voice and inflection.
Distinguishing Neural TTS from Standard TTS
Neural TTS stands apart from standard TTS by using neural networks, resulting in more natural-sounding, expressive speech synthesis.
Exploring Neural Network-Based TTS
Neural network-based TTS refers to systems that utilize neural networks to generate human-like speech, typically leading to improved quality over systems that don't use this technology.