Facebook Speech Translation with SeamlessExpressive: Complete Guide

Introduction
The SeamlessExpressive model is a revolutionary advancement in the field of speech translation, setting itself apart through its unique architecture. This architecture comprises two primary modules, each designed to tackle specific aspects of the translation process. Let’s delve deeper into these modules to understand their functionalities and the innovative technology behind them:
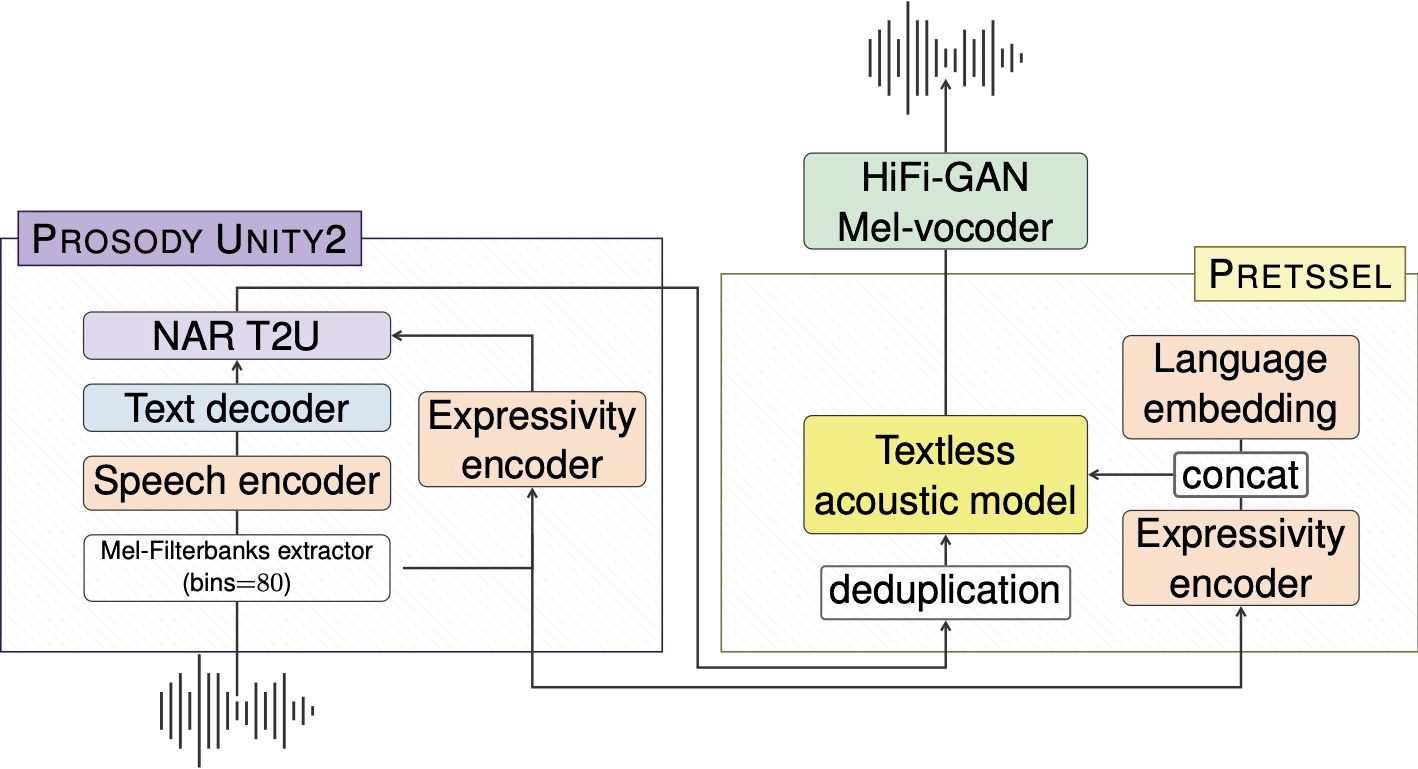
The Architecture of SeamlessExpressive
SeamlessExpressive is not just a singular model but a sophisticated combination of two integral components, each playing a crucial role in the translation process. These are:
- Prosody UnitY2: At the heart of SeamlessExpressive lies the Prosody UnitY2, an expressive speech-to-unit translation model. This component is unique in its ability to incorporate expressivity into the translation process, handling elements like speech rate and pauses. This ensures that the translation isn't just linguistically accurate but also retains the emotional and expressive nuances of the original speech.
- PRETSSEL (Paralinguistic REpresentation-based TExtleSS acoustic modEL): The second component, PRETSSEL, is an expressive unit-to-speech generator. Its primary function is to disentangle the semantic content from the expressivity components in speech. This means that PRETSSEL can efficiently transfer the style and tone of the original voice into the translated speech, thereby maintaining the speaker's unique expressiveness across different languages.
Application and Inference
Using SeamlessExpressive involves a relatively straightforward process, albeit requiring some technical know-how. The model provides a script for efficient batched inference, allowing users to translate speech into various target languages such as Spanish, French, German, Italian, and Mandarin. The script includes customizable parameters like the target language, dataset file paths, and output directories, making it adaptable for different use cases.
Benchmark Datasets and mExpresso
A crucial aspect of assessing the effectiveness of any translation model is the dataset used for benchmarking. In the case of SeamlessExpressive, the model is benchmarked using a dataset known as mExpresso. This dataset is a multilingual extension of the Expresso dataset and includes seven different styles of read speech (default, happy, sad, confused, enunciated, whisper, and laughing) across English and five other languages. The mExpresso dataset offers a comprehensive platform to evaluate the model's ability to handle various speech styles and emotional expressions in multiple languages.
Evaluating Performance
The evaluation of SeamlessExpressive’s performance is conducted using a range of metrics:
- ASR-BLEU (Automatic Speech Recognition - Bilingual Evaluation Understudy): This metric assesses the linguistic accuracy of the translated speech.
- Vocal Style Similarity: This evaluation focuses on how well the model preserves the speaker's unique vocal style in the translated speech.
- AutoPCP (Automatic Phonetic Content Preservation): This metric evaluates how well the phonetic content is preserved in translation.
- Pause and Rate Scores: These scores measure how accurately the model replicates the original speech's rate and pause patterns, which are crucial for maintaining the natural flow and expressiveness of speech
The Wide-Ranging Applications of the SeamlessExpressive Model
The development of the SeamlessExpressive model represents a significant breakthrough in the field of speech-to-speech translation, with its unique ability to preserve the emotional and expressive nuances of the original speech. This innovative technology has the potential to revolutionize various sectors by facilitating more natural and effective cross-lingual communication. Let's explore some of the key applications of this groundbreaking model:
International Diplomacy and Multilateral Negotiations
In the realm of international diplomacy, where precise communication and the subtleties of language are paramount, SeamlessExpressive can play a crucial role. By accurately translating speeches and maintaining the original tone and expressiveness, it can help in avoiding misunderstandings that often arise from linguistic barriers. The model's ability to convey the emotional context and nuances of speech makes it an invaluable tool for diplomats and international leaders engaged in complex negotiations.
Global Business and Cross-Border Communications
Businesses operating in the global market often face challenges in communicating across different languages and cultures. SeamlessExpressive can bridge this gap by providing accurate and expressive translations during meetings, presentations, and conference calls. This enhanced communication can lead to better understanding, trust-building, and more fruitful international partnerships.
Customer Service and Support
Customer service centers dealing with a diverse clientele can benefit significantly from SeamlessExpressive. The model's ability to translate and retain the original speech's emotional undertones can lead to more empathetic and effective customer interactions, improving customer satisfaction and loyalty.
Healthcare Services
In healthcare settings, where clear communication can be a matter of life and death, SeamlessExpressive can ensure that patients and healthcare providers who speak different languages can communicate effectively. Its ability to convey not just the words but also the emotions and concerns of the patients can lead to better diagnosis, treatment, and patient care.
Education and E-Learning
For educational purposes, particularly in e-learning platforms catering to an international audience, SeamlessExpressive can provide translations that maintain the instructor's enthusiasm and emphasis, making learning more engaging and effective for students who speak different languages.
Media and Entertainment
In the media and entertainment industry, SeamlessExpressive can be used to translate content such as films, documentaries, and interviews while preserving the original expressiveness and cultural nuances, providing a more authentic viewing experience for a global audience.
Accessibility for the Hearing Impaired
The model can also be adapted to assist individuals with hearing impairments by providing real-time translation and transcription of speeches, maintaining the speaker's emotional context, which is often lost in standard text.
Tourism and Cultural Exchange
For tourists and cultural exchange programs, SeamlessExpressive can enhance the experience by providing real-time, expressive translations of guides, historical narratives, and cultural explanations, making the experience more immersive and informative.
Emergency Response and Humanitarian Aid
In emergency situations and humanitarian missions, where responders and aid workers often interact with people speaking different languages, SeamlessExpressive can facilitate effective communication, ensuring that aid is provided efficiently and empathetically.
Research and Linguistic Studies
Researchers in linguistics and communication can use SeamlessExpressive to study how different languages and cultures express emotions, potentially leading to new insights in cross-cultural communication.
The SeamlessExpressive model, with its advanced capabilities, opens up new frontiers in effective and empathetic communication across various languages and cultures. Its applications span multiple sectors, demonstrating the transformative potential of AI in bridging linguistic and emotional gaps in a globalized world.
Utilizing the SeamlessExpressive Model
Utilizing the SeamlessExpressive model effectively requires a combination of technical understanding and practical application skills. This guide aims to walk you through the process of using this advanced speech-to-speech translation tool, ensuring you can leverage its full potential in various settings.
Step 1: Accessing the Model
- Download and Installation: The first step is to access the SeamlessExpressive model. This usually involves downloading the model from a repository like Hugging Face. Ensure that you have the necessary environment to run the model, which typically includes specific software and hardware requirements.
- Dependencies and Setup: Install any required dependencies. This often involves libraries and frameworks specific to AI and machine learning, such as TensorFlow or PyTorch. Make sure your system meets the necessary specifications for these installations.
Step 2: Preparing the Data
- Data Collection: Gather the speech data you intend to translate. This can be in the form of audio files or live audio streams. Ensure the audio quality is good, as this will affect the accuracy of the translation.
- Data Preprocessing: Process the audio files as per the model's requirements. This may involve converting them into a specific format or sampling rate. Clean the audio to remove noise and ensure clarity.
Step 3: Using the Model
- Loading the Model: Load the SeamlessExpressive model into your environment. This step usually involves initializing the model with pre-trained weights and configurations.
- Configuration: Set up the necessary parameters for the translation. This includes selecting the target language and adjusting settings related to speech style and expressiveness as per your requirements.
- Running the Translation: Input your preprocessed audio data into the model. The Prosody UnitY2 component will first translate the speech into a series of 'units,' capturing both linguistic content and prosodic features.
- Post-Translation Processing: After the initial translation, the PRETSSEL component will convert these units back into speech in the target language, embedding the original speech's prosodic characteristics.
Step 4: Output and Evaluation
- Receiving Output: The model will output the translated speech. Ensure you have the necessary setup to play or store this output, such as audio playback software or storage systems.
- Quality Assessment: Evaluate the quality of the translated speech. Check for linguistic accuracy, preservation of expressiveness, and overall fluency.
- Fine-Tuning: Based on your assessment, you might need to fine-tune the model for better performance. This can involve adjusting parameters or retraining certain components with additional data.
Step 5: Application in Real-World Scenarios
- Integration: Integrate the model into the desired application. This could be a customer service platform, a diplomatic communication channel, a healthcare provider’s interface, etc.
- User Training: If the model is to be used by individuals without a technical background, provide training on how to operate the model effectively in their specific context.
- Continuous Improvement: Regularly update and maintain the model to adapt to new languages, dialects, and evolving speech patterns.
Running on Hugging Face
Below is a sample code snippet demonstrating how to use a speech-to-speech translation model like SeamlessExpressive. This example is written in Python and assumes that you're using a model available through the Hugging Face Transformers library. The code will focus on loading the model, preprocessing the input speech data, and generating translated speech output.
Before running the code, ensure you have the necessary environment set up, including Python, and have installed the transformers and torch libraries. You might also need additional libraries for audio processing, such as librosa.
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
import torch
import librosa
# Function to load the model and tokenizer
def load_model(model_name):
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
return model, tokenizer
# Function to preprocess audio file
def preprocess_audio(audio_file):
# Load the audio file using librosa
speech, rate = librosa.load(audio_file, sr=16000) # Set sample rate to 16000
# Process the audio as per the model's requirements (e.g., normalization)
# ...
return speech
# Function to perform translation
def translate_speech(model, tokenizer, speech):
# Tokenize the speech input
inputs = tokenizer(speech, return_tensors="pt")
# Generate translation using the model
outputs = model.generate(inputs["input_ids"])
# Decode the output tokens to text
translated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
return translated_text
# Main execution
def main():
# Model name (change as per the actual model you are using)
model_name = "facebook/seamless-expressive" # Example model name
# Load the model and tokenizer
model, tokenizer = load_model(model_name)
# Path to your input audio file (e.g., "path/to/your/input.wav")
audio_file = "input.wav"
# Preprocess the audio
speech = preprocess_audio(audio_file)
# Translate the speech
translated_speech = translate_speech(model, tokenizer, speech)
print("Translated Speech:", translated_speech)
# Run the main function
if __name__ == "__main__":
main()
This code is a basic framework and will need modifications based on the specific model's requirements and your application needs. For instance, if the model requires a specific audio format or additional preprocessing steps, you would need to integrate those into the preprocess_audio function. Similarly, the translation step might differ based on whether the model outputs text or synthesized speech. Always refer to the documentation provided with the specific model for detailed instructions and requirements.
Conclusion
SeamlessExpressive represents a significant leap in speech-to-speech translation technology. By not only focusing on the linguistic accuracy but also on preserving the expressiveness and style of the original speech, it opens new possibilities for more natural and effective cross-lingual communication. As the world becomes increasingly interconnected, technologies like SeamlessExpressive play a vital role in breaking down language barriers and enhancing global understanding.