Comprehensive Analysis of Long-Form Content Creation Using Text-to-Speech Services
A complete analysis on creating long-form content using using text-to-speech services (Eleven Labs, Unreal Speech and Play HT).
Project Overview
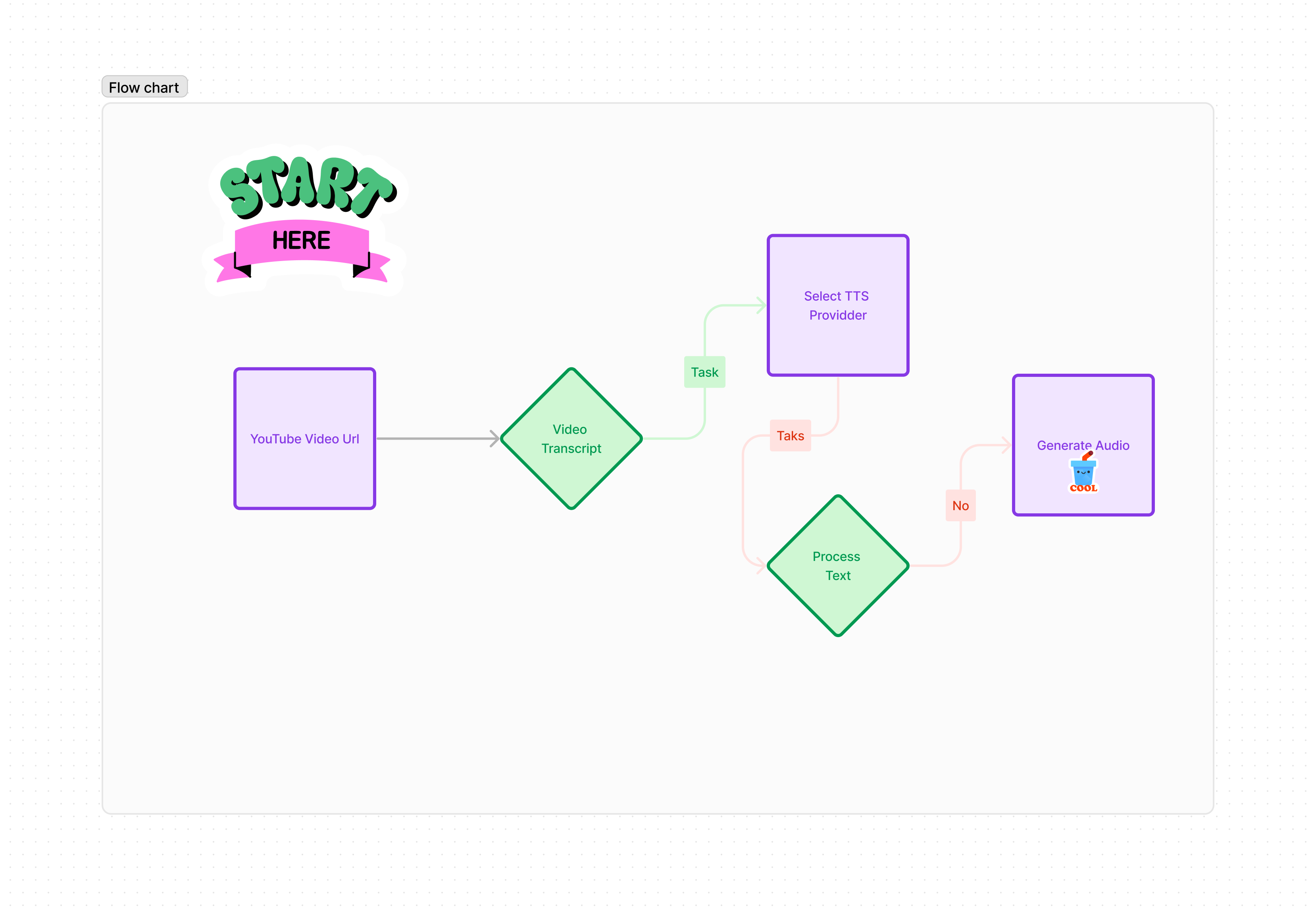
The objective of this project is to develop a long-form audio application utilizing various text-to-speech (TTS) models. Our focus will be on comparing these models across three key dimensions: pricing, quality, and speed. The TTS models under evaluation include:
- Unreal Speech
- Eleven Labs
- Play HT
The application, named Eric, is designed as an AI assistant. Its primary function is to transform YouTube videos into audio and provide answers to questions related to the video content. The selection of "Eric" for this project was influenced by considerations of speed, quality, and pricing.
Understanding Text-to-Speech (TTS) Technology
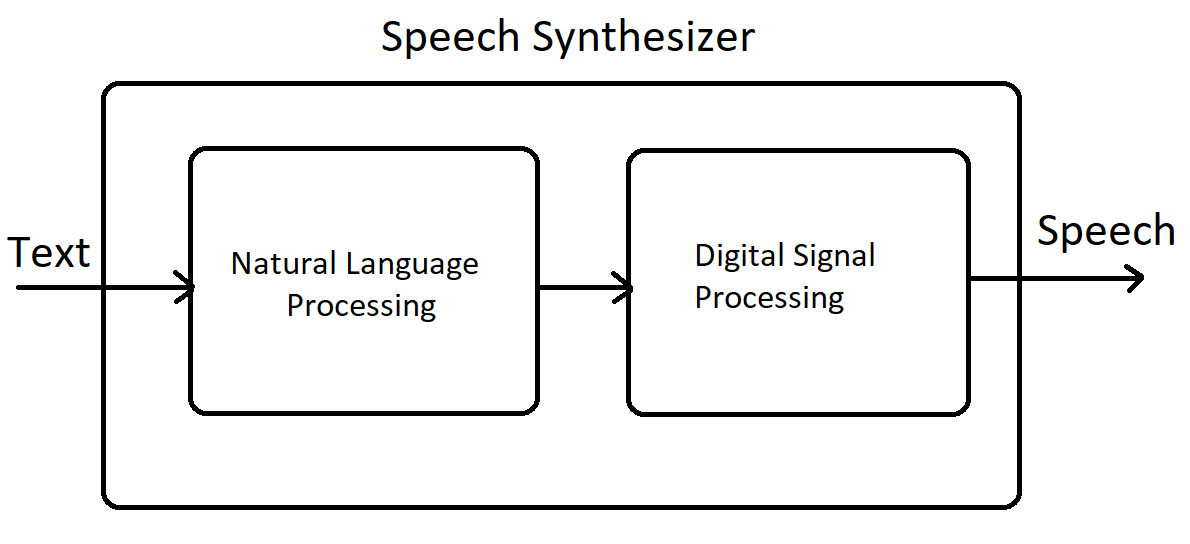
Text-to-Speech technology is a sophisticated process that transforms written text into audible speech. This technology integrates natural language processing (NLP) and digital signal processing to produce speech that sounds natural and human-like. The key components of TTS technology include:
- Text Analysis: This is the foundational step where the input text is processed. It involves segmenting the text into sentences and words and understanding the context. This stage, often incorporating NLP, is crucial for determining the correct pronunciation, especially in languages with complex spelling rules.
- Prosody Prediction: Prosody encompasses the rhythm, stress, and intonation of speech. For TTS to sound natural, it must accurately predict these elements based on the sentence structure and intended meaning. This involves determining the right pitch, duration, and emphasis.
- Neural TTS: Contemporary TTS systems frequently utilize deep learning, particularly neural networks. Models like WaveNet leverage these networks to generate speech directly from text, learning intricate speech patterns from extensive datasets. This advancement has significantly improved the naturalness and expressiveness of synthesized speech.
- Voice Customization and Adaptation: Advanced TTS systems offer options for voice customization. Users can adjust the speaking style or even create new voices, which is particularly beneficial in applications like virtual assistants, where a distinct voice identity is desirable.
In contrast, TTS technology combines linguistic analysis with advanced computational techniques to convert written text into natural-sounding speech. Its applications range from aiding visually impaired users to voice response systems and virtual assistants.
Project Setup
To kickstart our project on evaluating text-to-speech (TTS) services, the initial step involves acquiring the necessary API keys from the respective service providers. Here's a streamlined approach to get started:
- Visit the Service Providers' Websites: Navigate to the websites of the TTS services we are evaluating - Unreal Speech, Eleven Labs, Play HT, Google TTS, Amazon TTS, and Microsoft TTS.
- Registration and API Key Acquisition: Register or sign in on these platforms. Once logged in, navigate to the section where you can generate or request an API key. This key is essential as it will allow us to programmatically access the TTS services.
- Secure Storage of API Keys: Ensure to securely store these keys, as they are sensitive credentials that grant access to each service's API.
- Code Snippets and Testing: After obtaining the API keys, I will provide code snippets for each TTS service. These snippets will be ready-to-use examples, demonstrating how to integrate and utilize the TTS functionalities in your projects.
- Hands-On Testing: You are encouraged to use these snippets to test the functionality of each TTS service. This hands-on experience will give you a practical understanding of the nuances of each service, including voice quality, response time, and ease of integration.
By following these steps, you'll be well-prepared to dive into the project and conduct a thorough and effective analysis of the various text-to-speech services. This process not only sets the foundation for our comparative study but also provides you with valuable skills and insights into the integration and utilization of TTS technologies.
For convenient access and to facilitate our project on evaluating text-to-speech (TTS) services, I have compiled a list of direct links to the respective TTS models we will be utilizing. This organized approach will streamline the process of exploring and obtaining the necessary resources for each service:
Understanding Streamlit
Streamlit is an open-source Python library that simplifies the process of creating and sharing beautiful, custom web applications for machine learning and data science. It's designed to turn data scripts into shareable web apps in minutes, without requiring extensive knowledge of web development frameworks.
Key Features of Streamlit:
- Ease of Use: Streamlit is known for its simplicity. You can create a web app with just a few lines of Python code. It's designed to be intuitive for those who are already familiar with Python, especially data scientists and machine learning engineers.
- Rapid Prototyping: Streamlit allows for quick iteration and prototyping of apps. You can write your Python scripts as usual, and with a few additional lines of code, turn them into a web app.
- Interactive Widgets: It provides built-in widgets like sliders, buttons, and text inputs, making it easy to interact with your data and models. These widgets allow users to manipulate the data or model parameters in real-time.
- Data Integration: Streamlit supports a wide range of data formats and sources, making it easy to integrate with your existing data pipelines. It can handle large datasets efficiently.
- Customization and Layout: While Streamlit is straightforward to use, it also offers options for customization. You can arrange the layout of your app, style it, and add markdown text to create professional-looking applications.
- Sharing and Deployment: Streamlit apps can be easily shared with others. You can deploy your app on various platforms like Heroku, AWS, or Google Cloud, or share it using Streamlit sharing, which provides a hassle-free hosting solution.
- Community and Ecosystem: Streamlit has a growing community and ecosystem, with a variety of plugins and extensions that add extra functionality to your apps.
Streamlit has become popular among data scientists and machine learning engineers because it bridges the gap between backend data processing and frontend web app development, making it easier to showcase data insights and models.
Setting up Streamlit
The first step in setting up Streamlit is installing it. You need Python installed on your system as Streamlit is a Python library. You can install Streamlit using pip, Python's package manager. Here's the command you need to run:
pip install streamlit
Once you've installed Streamlit, creating your first app is straightforward. Here's a simple example to get you started:
- Create a Python file: Create a new Python file for your app, like
app.py. - Import Streamlit: At the top of your file, import Streamlit using:
import streamlit as st
Add Streamlit Elements: Use Streamlit's functions to add elements to your app. Here's a basic example:pythonCopy code
Run Your App: To view your app, open your terminal, navigate to the directory containing your Python file, and run base code: streamlit run app.py
This command launches your app in your default web browser.
Code analysis and breakdown
Imports and Utility Functions
import time
import streamlit as st
from utils.eleven_labs import elevenlabs_voicer
from utils.myplayZ_ht import playht_voice
from utils.unreal_speach import unrealspeech_voice
from utils.youtube_transcript import get_youtube_transcript
The script begins by importing necessary modules like time for tracking the duration of operations and streamlit (aliased as st) for building the web interface. It also imports custom functions from the utils directory. These functions (elevenlabs_voicer, playht_voice, unrealspeech_voice) are designed to interact with different TTS providers. The get_youtube_transcript function is used for fetching transcripts from YouTube videos.
Audio Playback function
audio_filename = 'audio.mp3'
def play_audio(file_path):
audio_file = open(file_path, 'rb')
audio_bytes = audio_file.read()
st.audio(audio_bytes, format='audio/mp3')
Here, play_audio is a function to play an audio file in the Streamlit application. It reads the audio file in binary mode and uses Streamlit's audio function to play it.
User Interface and Interaction
The next part of the code sets up the user interface and interaction:
- Selecting a TTS Provider: The user can choose a TTS provider from a predefined list (
selections). - Input Field: A sidebar is created for users to input the YouTube video URL.
- Fetching and Displaying Transcript: Upon clicking the 'Submit' button, the script fetches the transcript of the YouTube video.
selections = ['Unreal-Speech', 'Eleven Labs', 'Play HT']
with st.sidebar:
st.title("Insert a YouTube video link ")
selected_model = st.selectbox(
'Choose a TTS provider', selections)
user_input = st.text_input("video url")
if selected_model:
st.session_state.select_value = selected_model
if st.button('Submit'):
with st.spinner('Fetching transcript...'):
# Fetch and display the transcript
transcript = get_youtube_transcript(user_input)
st.session_state.transcript = transcript
Chat Messages and Transcript Handling
The script keeps track of chat messages and displays the fetched transcript. It then processes the transcript through the selected TTS provider.
Audio Generation and Playback
Depending on the selected TTS provider, the script generates the audio version of the transcript. The time taken for this process is calculated and displayed. Finally, the generated audio is played back.
How It Works: A Step-by-Step Overview
- Initial Setup: The script imports necessary modules and defines functions.
- User Input: Through the Streamlit interface, the user inputs a YouTube video URL and selects a TTS provider.
- Transcript Fetching: On submitting the URL, the script fetches the corresponding transcript.
- TTS Processing: The transcript is processed by the chosen TTS provider.
- Audio Playback: The generated audio is played back in the web application.
The full-code for this project can be found in our Github Repository: https://github.com/unrealspeech/youtube-transcript-to-audio
Detailed comparison between Unreal Speech, Eleven Labs and Play HT
After conducting over six hours of thorough research, I have compiled comprehensive datasets to effectively compare three Text-to-Speech (TTS) services. This includes an analysis of each service's strengths and weaknesses. I used a sample of 5,076 characters for a detailed comparison of these services.
Speed
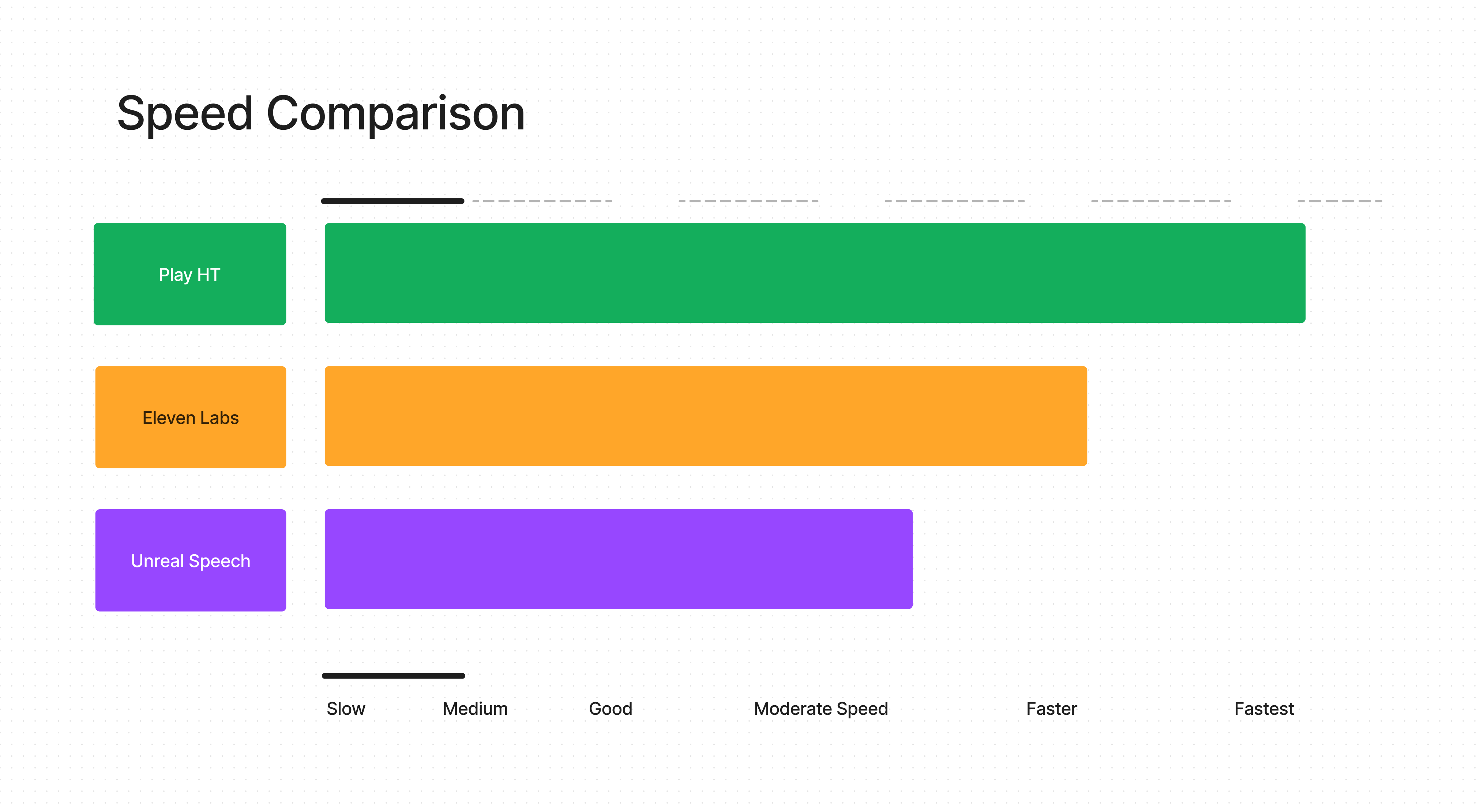
Play HT's performance in the Text-to-Speech (TTS) sector is commendable, especially in terms of processing speed. It efficiently generates a substantial volume of text, precisely 5,075 characters, in an impressively short span of less than five seconds. This showcases Play HT's advanced technology and capability for quick processing, a valuable asset in situations where rapid text-to-speech conversion is crucial. At Unreal Speech, we also prioritize technological excellence and strive to offer a service that not only matches the industry's speed standards but also enriches the user experience with high-quality output and versatile features. Both Play HT and Unreal Speech contribute uniquely to the TTS field, each with its own strengths, catering to the diverse needs of users
In the dynamic landscape of Text-to-Speech services, each platform brings its unique strengths to the table. While Eleven Labs is recognized for its faster processing capabilities, Unreal Speech distinguishes itself with its exceptional features that cater to a wide range of user needs. It's not just about speed; it's about the overall experience, quality, and versatility that Unreal Speech offers. Alongside these, Play HT also stands out, particularly in terms of its rapid text generation. Each service, be it Eleven Labs, Play HT, or Unreal Speech, excels in different areas, making the TTS ecosystem diverse and well-suited to various preferences and requirements.
Voice Quality
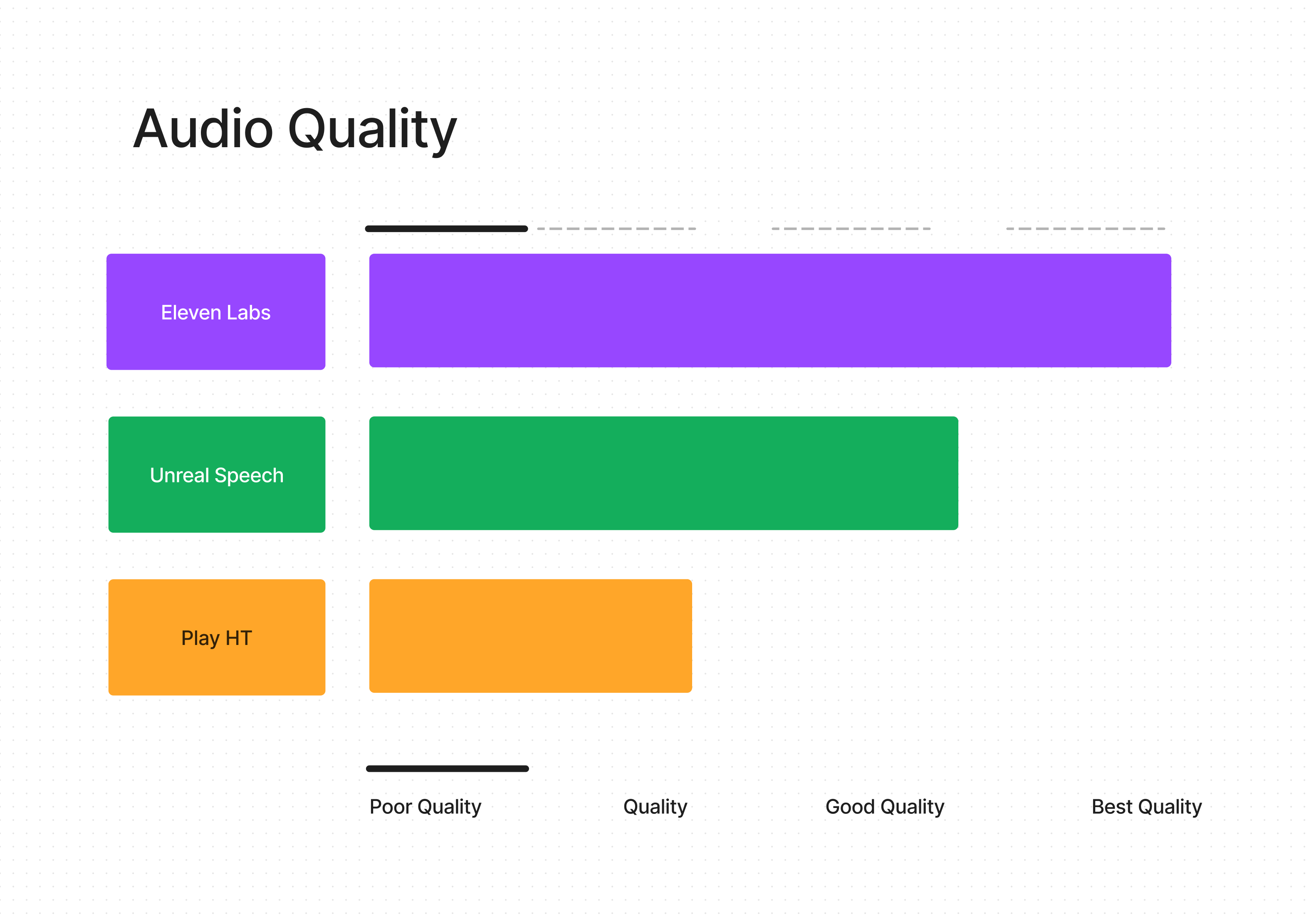
Welcome to the vibrant world of Text-to-Speech (TTS) services, where each voice tells a story and quality is the key narrator. As an enthusiast and advocate of Unreal Speech, I'm excited to guide you through this melodious journey of voice quality comparisons.
First, let's tip our hats to Eleven Labs. In the realm of audio clarity, they're like the maestros conducting an orchestra. Their service is akin to a high-definition sound experience – it's the kind of quality that can make audiophiles and lovers of crystal-clear narration swoon.
Now, let's talk about where my passion lies – Unreal Speech. While Eleven Labs leads with their audio finesse, Unreal Speech brings its own flavor to the table. We're not just about clear audio; we're about creating a voice that adapts to your world. It's like having an artist who can paint in multiple styles – whether it's a formal presentation or a casual podcast, we've got a voice for every shade of expression. It's this blend of quality and customization that makes us stand out.
And of course, there's Play HT. Speed is their game, and they play it well, delivering content at a pace that's hard to beat. While they may not be the frontrunners in voice quality like Eleven Labs or as versatile as Unreal Speech, they offer a dependable and efficient service. Think of them as the reliable express train in the world of TTS – fast, effective, and on point.
So, as we wrap up this tour of the TTS landscape, remember that it's all about finding the voice that resonates with your unique needs. Whether it's the pristine quality of Eleven Labs, the adaptable and rich tones of Unreal Speech, or the swift delivery of Play HT, the perfect voice is out there waiting for you. And if you ask me, Unreal Speech is a symphony worth exploring.
Long Form Audio
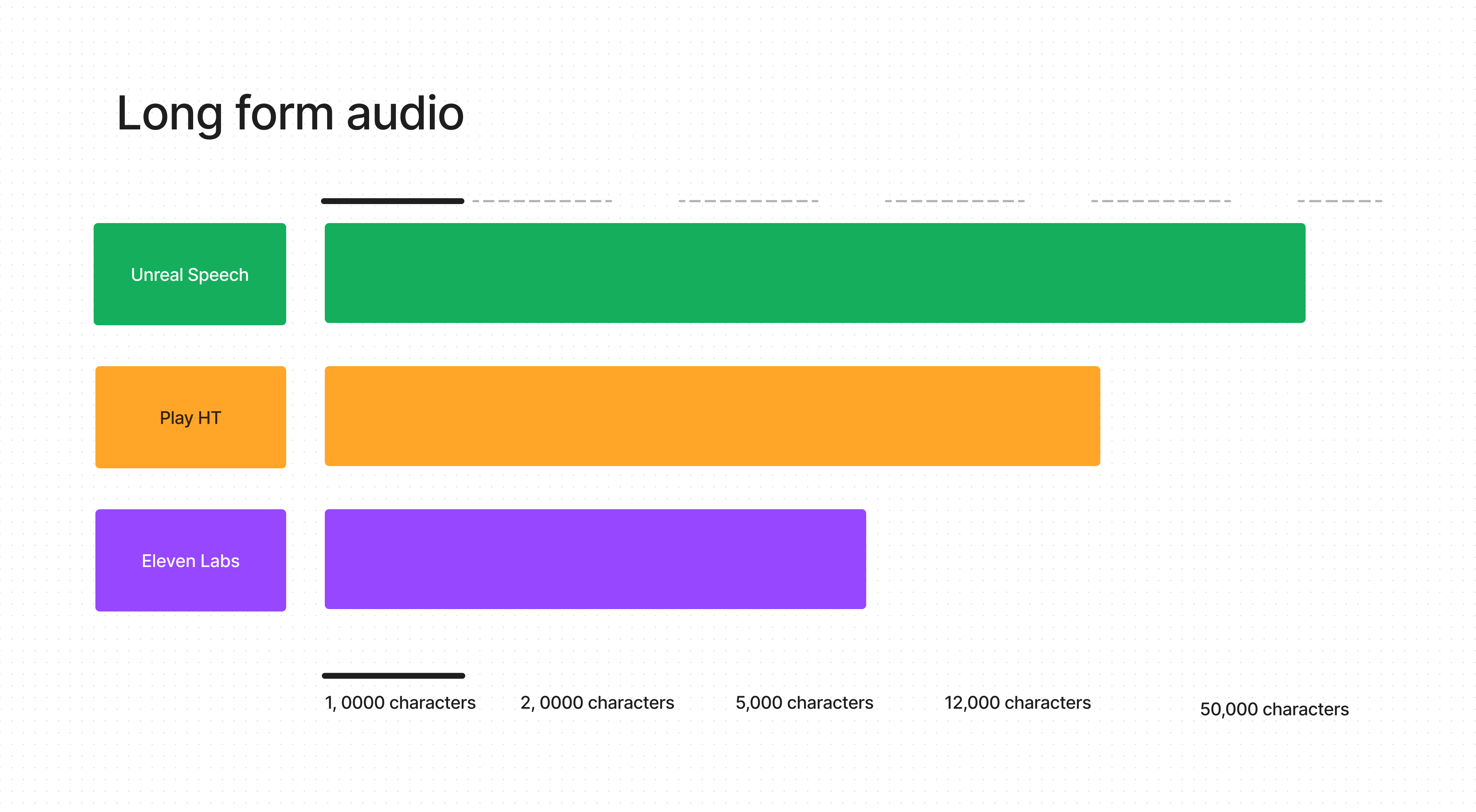
Imagine you're crafting an audiobook, a lengthy podcast, or an extended narration. You'll need a TTS service that doesn't just stop after a few sentences. This is where the character limit per request becomes a game-changer.
Let's start with Unreal Speech, a platform I'm particularly passionate about. Here, we're talking about a generous limit of over 48,000 characters per request. That's like having the freedom to narrate several chapters of a book or an entire podcast episode in one go! It's perfect for those projects that require uninterrupted, seamless speech, making it a top pick for long-form content.
On the other hand, Play HT offers a respectable 12,000 characters per request. While it may not cater to extremely lengthy sessions like Unreal Speech, it's still quite capable for moderately long content. Think of it as a solid choice for shorter podcast episodes or sections of an audiobook.
And then, there's Eleven Labs, offering up to 5,000 characters per request. It's more suited for shorter pieces – perhaps a blog post, a brief news update, or a short story. It's the go-to for quick, snappy content that doesn't require the longer narrative space.
In the end, each TTS service has its strengths, and the choice depends on your specific needs. If your world revolves around creating extended audio content, the expansive character limit of Unreal Speech might just be what you're looking for. For shorter, yet still substantial pieces, Play HT is a reliable option. And for those quick, concise narrations, Eleven Labs has you covered.
So, whether you're narrating the next bestselling audiobook, creating an engaging podcast series, or producing short, informative content, there's a TTS tool out there that fits the bill. And if you ask me, for those longer narratives, Unreal Speech is a journey worth embarking on.
Pricing
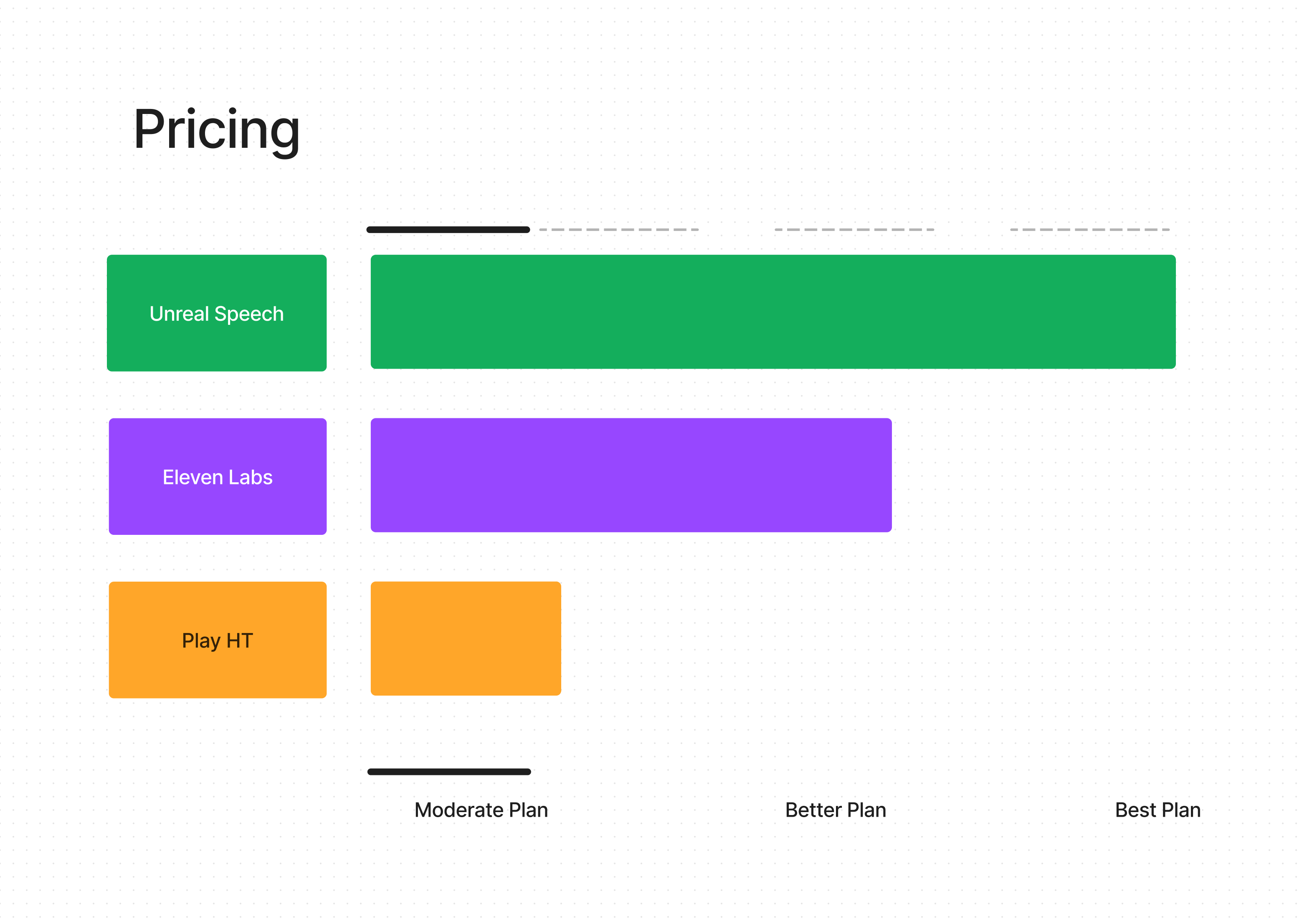
Let's navigate another crucial aspect of Text-to-Speech (TTS) services – the pricing. Whether you're a budding podcaster, an established audiobook author, or just exploring the TTS landscape, understanding the cost involved is key. As an Unreal Speech advocate, I'm here to guide you through this with a fair and balanced perspective.
First up, let's talk about Unreal Speech. I might be a bit biased here, but when it comes to getting the most bang for your buck, Unreal Speech is a standout choice. We offer competitive pricing that aligns beautifully with the quality and range of services provided. It's like finding that sweet spot where affordability meets excellence. Whether you're handling large-scale projects or just starting out, Unreal Speech provides a cost-effective solution without compromising on quality.
Moving on to Eleven Labs, they slot in as a close second. Their pricing model is designed to cater to a range of users, balancing cost with their high-quality output. It's like choosing a premium coffee that's worth those extra pennies – you're paying for that richer flavor and superior experience.
Lastly, we have Play HT. While they offer commendable speed and efficiency, their pricing structure falls a bit behind when compared to the value offered by Unreal Speech and Eleven Labs. Think of it like opting for a fast food meal – it's quick and fills the gap, but when it comes to savoring a more fulfilling experience, you might look elsewhere.
In the grand scheme of things, pricing in the TTS world isn't just about the cheapest option. It's about finding a service that aligns with your needs and offers the best return on investment. For those who prioritize extensive character limits and quality, Unreal Speech is a wallet-friendly champion. For premium quality seekers, Eleven Labs is a worthy consideration. And for those valuing speed, Play HT is still a player in the game.
So, whether you're tightening the purse strings or ready to splurge a little, there's a TTS service that fits your budget and your project. And if you're asking for my two cents, Unreal Speech offers a harmonious blend of quality, capacity, and affordability that's hard to beat.
In conclusion
And just like that, we've reached the end of our little tech adventure in the land of Text-to-Speech services. It's been a journey filled with voices of all pitches and tones, character limits that stretch like the endless horizon, and pricing puzzles that we've pieced together. As we wrap up, let's take a moment to revisit the highlights, especially those shining moments of Unreal Speech.
Think of Unreal Speech as your trusty Swiss Army knife in the TTS world. It's versatile, reliable, and just what you need when you're diving into the depths of long-form audio. With a generous character limit that's like an open road for your narratives, Unreal Speech stands as a beacon for those epic storytelling sessions. Whether you're crafting an audiobook that rivals the classics or a podcast series that keeps listeners hooked, Unreal Speech is your go-to companion.
And let's not forget the pricing – oh, the sweet spot of affordability and quality! It's like finding that perfect cup of coffee that doesn't break the bank but still gives you that rich, satisfying taste. Unreal Speech offers this balance, ensuring that your wallet stays happy while your creative needs are fully met.
As we bid farewell to this exploration, remember that each TTS service has its melody to play in the grand orchestra of technology. Eleven Labs with its high-definition audio, Play HT with its speedy delivery, and of course, Unreal Speech, with its harmonious blend of length, quality, and affordability.
So, whether you're a seasoned content creator or just starting to dip your toes into the ocean of TTS, there's a tool out there that sings in tune with your needs. And if you're ever in doubt, remember that Unreal Speech is like that friend who's always ready to lend a voice – versatile, cost-effective, and always up for a long chat.
Here's to finding the voice that tells your story the best – may your narratives be long, your quality be high, and your budgets be just right. Until next time, keep speaking and creating!