MARY Text-to-Speech (MARYTTS): Complete Guide

Introduction
MARY Text-to-Speech (MARYTTS) is an open-source, multilingual Text-to-Speech Synthesis platform written in Java. It was originally developed as a collaborative project of DFKI's Language Technology Lab and the It is now maintained by the Multimodal Speech Processing Group in the Cluster of Excellence MMCI. As of version 5.2, MaryTTS supports German, British and American English, French, Italian, Luxembourgish, Russian, Swedish, Telugu, and Turkish; more languages are in preparation. MaryTTS comes with toolkits for quickly adding support for new languages and for building unit. MaryTTS is available as a TTS engine for the Sonos plugin.
key features of marytts
The key features of MARY Text-to-Speech (MARYTTS) include:
- Open-Source Platform: MARYTTS is an open-source, multilingual Text-to-Speech Synthesis platform written in Java, making it accessible for developers and researchers.
- Multilingual Support: MARYTTS supports various languages, including German, British and American English, French, Italian, Luxembourgish, Russian, Swedish, Telugu, and Turkish, with ongoing preparations for additional languages.
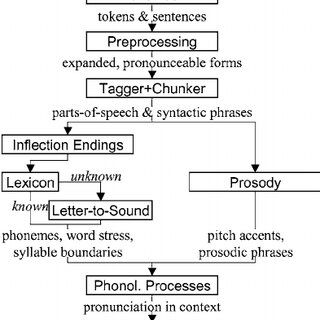
- Modular Architecture: The platform is built on a modular architecture, which is beneficial for research on speech synthesis and allows for flexibility and extensibility.
- Voicebuilding Capabilities: MARYTTS comes with toolkits for quickly adding support for new languages and for building unit, enabling the creation of new voices and language support.
- Client-Server System: It operates as a client-server system, written in pure Java, and is available as a TTS engine for the Sonos plugin.
These features make MARYTTS a versatile and adaptable platform for text-to-speech synthesis, catering to a wide range of language requirements and research needs.
Features of marytts
MARY Text-to-Speech (MARYTTS) is an open-source, multilingual Text-to-Speech Synthesis platform written in Java. Some of its features include:
- Support for multiple languages, including German, British and American English, French, Italian, Luxembourgish, Russian, Swedish, Telugu, and Turkish, with more languages in preparation.
- Toolkits for quickly adding support for new languages and building unit.
- Modular architecture for research on speech synthesis.
- Voicebuilding capabilities.
MARYTTS is a client-server system written in pure Java and is available as a TTS engine for the Sonos plugin
How to install marytts on a local machine?
To install MARY Text-to-Speech (MARYTTS) on a local machine, there are several options available depending on the operating system. Here are the general steps:
- Download the MARYTTS installer from the official website or GitHub repository.
- Unzip the downloaded file to a directory of your choice.
- Install a language by running the command
./marytts install <language>in the terminal, where<language>is the language you want to install. - Start the MARYTTS server by running the command
./maryttsin the terminal.
For more detailed instructions, including how to run MARYTTS as a service, refer to the official documentation on GitHub. There are also video tutorials available on YouTube for installing MARYTTS on Windows and Ubuntu
what are the steps to install marytts on windows?
To install MARY Text-to-Speech (MARYTTS) on Ubuntu, you can follow these general steps based on the provided search results:
- Download and Unzip:
- Download the MaryTTS-Installer and unzip it to a directory of your choice.
2. Install Language:
- Open a terminal and navigate to the directory where you unzipped MaryTTS.
- Install a language using the command
./marytts install <language>. For example, to install the German male voice, you can use./marytts install voice-bits3-hsmm.
3. Start the Server:
- To start the MaryTTS server, run the command
./maryttsin the same directory where you unzipped MaryTTS.
4. Run MaryTTS as a Service (Optional):
- You can create a service to start the MaryTTS server at boot up. This involves creating a systemd service file and enabling the service.
These steps provide a basic outline for installing and running MARYTTS on Ubuntu. For more detailed instructions, you can refer to the official documentation, video tutorials, or the specific GitHub repository for MaryTTS
How to use model?
To use MARY Text-to-Speech (MARYTTS), you can follow these general steps:
- Start the Server: Open the "bin" folder and start the MARYTTS server.
- Run the Client: Once the server is running, start the MARYTTS client.
- Select the Voice: From the dropdown menu, select the voice you want to use.
- Choose Output Type: Select the output type to be audio.
- Play the Speech: Click play and wait for the voice to speak.
These steps provide a basic outline for using MARYTTS. For more detailed instructions, you can refer to the official documentation or specific tutorials available online
Top 10 use cases of MaryTTS
These are the use cases for the MARY Text-to-Speech (MARYTTS) model based on the general capabilities of text-to-speech synthesis models like MARYTTS, here are 10 potential use cases:
- Accessibility Tools: Enhancing accessibility for visually impaired individuals by converting text content into speech.
- Language Learning Applications: Assisting language learners with pronunciation and listening comprehension exercises.
- Interactive Voice Response (IVR) Systems: Powering automated phone systems for tasks such as customer support and call routing.
- E-Learning Platforms: Integrating speech synthesis for reading out educational content and instructions.
- Assistive Technologies: Supporting the development of assistive devices for individuals with speech or communication disabilities.
- Audio Book Production: Automating the conversion of written content into audio books.
- Smart Home Devices: Enabling voice feedback and responses for smart speakers and home automation systems.
- Language Translation Services: Providing spoken translations for multilingual communication.
- Entertainment and Gaming: Incorporating realistic and dynamic speech for virtual characters and interactive experiences.
- Speech-Enabled Applications: Empowering various applications with speech output, such as navigation systems and personal assistants.These use cases demonstrate the diverse applications of text-to-speech synthesis models like MARYTTS across different industries and domains.
How to use MARYTTS in python
You can use the py-marytts package, which provides a Python interface for MARYTTS. Below are some examples of how to use the py-marytts package to interact with MARYTTS:
Install the Package:
- You can install the
py-maryttspackage using pip:
pip install py-marytts
Example Usage:
- Import the necessary modules and perform tasks such as text-to-speech synthesis and G2P (Grapheme to Phoneme) conversion:
from marytts import MaryTTS
# Set the MARYTTS server location
marytts = MaryTTS('http://localhost:59125')
# Synthesize text to speech
audio_data = marytts.tts('Hello, how are you?')
# Perform G2P conversion
phonemes = marytts.g2p('Hello')
Additional Information:
- For more details and advanced usage, you can refer to the
py-maryttspackage documentation and examples on its official GitHub page.By using thepy-maryttspackage, you can create a Python API to interact with MARYTTS and perform text-to-speech synthesis and other related tasks.
Conclusion
The development and evolution of MARY Text-to-Speech (MARYTTS) have been significant, with its modular and open-source nature contributing to its growth and popularity among researchers and developers. However, as outlined in the provided research papers, the system has encountered challenges related to increasing complexity, maintenance, and voicebuilding.
The efforts to address these challenges through the introduction of a new architecture and continuous delivery methodology demonstrate a commitment to enhancing the system's flexibility and consistency.
The research and ongoing development of MARYTTS, as evidenced by the work presented in the provided papers, reflect a dedication to refining the system and overcoming its limitations. The introduction of a new architecture and voicebuilding workflow, aimed at simplifying maintenance and providing greater flexibility, underscores the adaptability and responsiveness of the MARYTTS platform to meet the evolving needs of its users.In conclusion, the research and advancements in MARYTTS not only highlight the ongoing commitment to innovation and improvement within the field of text-to-speech synthesis but also offer valuable insights into the challenges and solutions associated with maintaining and evolving complex, open-source systems.
The continued development of MARYTTS is poised to contribute to the advancement of speech synthesis technology and its diverse applications in the future.