SpeechX and Neural Text-to-Speech Synthesis: Microsoft's Innovation in AI Voice

Exploring SpeechX: Microsoft's Leap into Next-Gen Text-to-Speech Technologies
The unveiling of Microsoft's SpeechX marks a significant milestone in the evolution of text-to-speech (TTS) technologies. SpeechX emerges as a versatile and robust solution in the arsenal of neural TTS, addressing a spectrum of speech transformation tasks head-on. For the avid technologists — university research scientists and seasoned software engineers — SpeechX paves the way for exploration into the domain of zero-shot TTS capabilities. This empowerment in TTS sophistication is crucial for elevating the user experience across platforms, whether it be in customer service automation, educational tools, or interactive entertainment.
Delving deep into the mechanics, SpeechX stands out for its ability to transmute clean and noisy signals into clear and intelligible speech — a testament to Microsoft's commitment to harnessing artificial intelligence (AI) for real-world applications. This breakthrough, aligned with deep learning innovations, signifies a leap towards speech synthesis that can seamlessly adapt to varied environmental audio conditions. The academia and industry professionals who mold the future of AI-driven applications will find in SpeechX a compelling model that encapsulates the most cutting-edge advancements in neural TTS, offering a glimpse into the future where machines articulate with human-like precision and flexibility.
| Topics | Discussions |
|---|---|
| Overview of Microsoft's SpeechX | Introducing SpeechX, Microsoft's innovative model for neural TTS, which emphasizes zero-shot learning and robust speech generation capabilities. |
| Technological Advancements in TTS | Exploring the latest advancements that SpeechX brings to the table, pushing the boundaries of what's possible in voice technology using neural networks. |
| Enhancing AI in Voice Technology | Insights into how SpeechX incorporates cutting-edge AI for creating voice technology solutions that are more accurate, versatile, and user-friendly. |
| Common Questions Re: Neural Voice Technologies | Answers to frequently asked questions about neural TTS, differentiating SpeechX from traditional models and identifying its AI-driven core. |
Overview of Microsoft's SpeechX
Delving into the realm of neural text-to-speech (TTS) with Microsoft's SpeechX introduces a host of specialized terminologies that are fundamental to understanding and utilizing this advanced technology. SpeechX stands as a groundbreaking development with its novel approach to speech generation, and getting familiar with the associated jargon is essential for professionals who are integrating such technologies into their workflows. Below is a glossary of terms that serve as the cornerstone of discussions surrounding the SpeechX model and the future of neural TTS.
| Term | Definition |
|---|---|
| SpeechX | Microsoft's avant-garde model for neural text-to-speech technology, introducing a new level of versatility and robustness to speech synthesis. |
| Zero-shot TTS | A type of TTS capable of generating speech in voices and styles not present in the training data, without prior adaptation or fine-tuning. |
| Noisy Signal Handling | The ability of TTS systems to interpret and clean audio inputs with background noise, delivering a clear output. |
| Neural TTS | TTS systems powered by neural networks, capable of producing human-like speech through complex pattern learning and prediction. |
| Deep Learning | A subset of machine learning involving neural network layers to analyze complex data, crucial for achieving natural-sounding speech synthesis. |
| AI | Artificial Intelligence, the simulation of human intelligence in machines designed to think and learn, crucial for the development of intelligent TTS. |
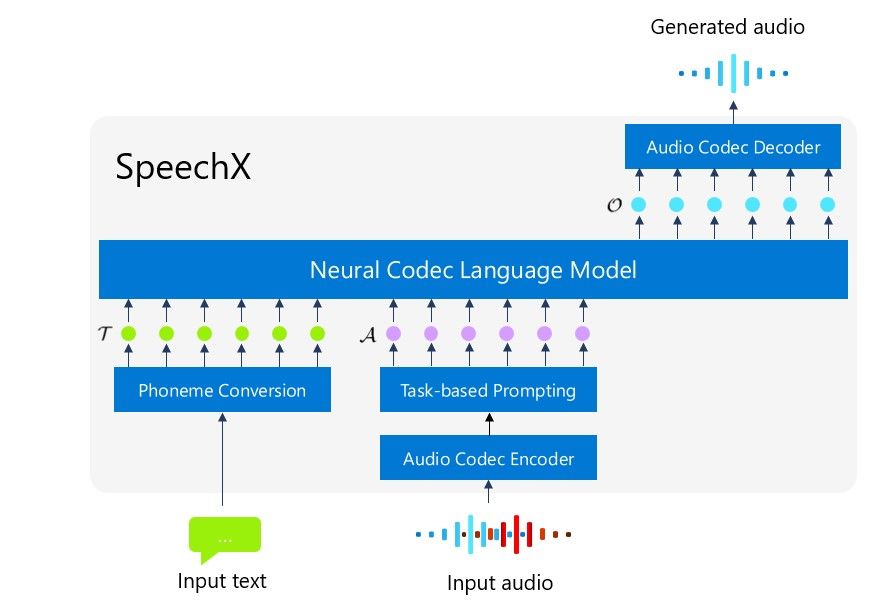
Technological Advancements in TTS
The advent of SpeechX signifies a remarkable step forward in the nuance and application of text-to-speech (TTS) systems. This technology stands at the forefront of advancements by addressing a limitation that has long challenged the domain: the ability to produce accurate and natural speech from text without customized datasets for different voices. SpeechX surpasses this barrier with its zero-shot TTS capabilities, synthesizing speech in a wide array of voices based solely on textual information while needing no voice-specific training data.
Beyond its groundbreaking zero-shot learning, SpeechX exhibits an exceptional ability to handle both clean and noisy signals. This characteristic is pivotal, making it a robust tool for real-world scenarios marked by sound interference and varied audio conditions. Microsoft's foray into these frontiers reflects a dedication to enhancing machine learning and deep neural networks to process and interpret auditory data more effectively than ever before.
SpeechX's capacity to fine-tune this performance across diverse environments and recording conditions hints at the extensive research and algorithmic sophistication that underpins Microsoft's latest offering in the neural TTS space. The incorporation of advanced noise reduction and signal processing techniques further exemplifies the system's readiness for deployment in scenarios reflective of everyday use, pushing the envelope of speech technology to new heights.
If Microsoft has released software development kits (SDKs) or application programming interfaces (APIs) for SpeechX, the documentation provided with these tools will be the best resource for tutorials and code samples geared towards the supported programming languages. They will outline necessary prerequisites, setup instructions, and usage guidelines with examples to assist developers in incorporating the technology into their software.
Enhancing AI in Voice Technology
Unreal Speech has emerged as a cost-effective foray into the realm of text-to-speech (TTS) technology, catering to an array of professionals with its innovative text-to-speech synthesis API. By offering dramatic cost reductions, Unreal Speech provides a significant economical advantage, especially to academic researchers who may now utilize powerful TTS features in their work without the limiting factor of high expenses typically associated with such technologies.
For software engineers and developers, the API presents an accessible means to integrate advanced speech capabilities into applications. This move can significantly lower development costs and operational overhead while maintaining high quality and performance. With competitive pricing and reliability, Unreal Speech positions itself as a valuable tool for developing scalable applications in Python, Java, or JavaScript.
Game developers and educators also stand to benefit from Unreal Speech's versatile API. The ability to produce high-quality voice output at lower cost opens up opportunities for creating more engaging gaming experiences and educational content. Additionally, the promise of support for multilingual voice options speaks to the future-proof nature of the API, anticipating the needs of a diverse user base and preparing for global applicability in various interactive scenarios.
Common Questions Re: Neural Voice Technologies
How Does Neural Text to Speech Operate?
Neural text to speech operates by leveraging deep neural networks to process text and generate corresponding speech that mimics human intonation, pitch, and cadence. It learns from examples to produce speech that feels natural and fluid.
What Technology Powers Current TTS Solutions?
Current TTS solutions are predominantly powered by advanced machine learning technologies, including deep learning frameworks. These enable the synthesis of speech with variable tones and inflections, closely resembling human speech patterns.
Which AI is Behind Text Turned Into Speech?
AI systems responsible for converting text into speech utilize complex algorithms, particularly under the branch of natural language processing (NLP), to understand the nuances of language and produce audible speech that mirrors natural human communication.