StyleTTS2 Simplified
We're about to dive into the world of StyleTTS2, and I'm here to make it as easy and enjoyable as possible for you. Forget about the daunting task of manual setups that can often be time-consuming and a bit overwhelming. I'll walk you through a simple, user-friendly process that's designed for everyone, whether you're a tech whiz or just starting out. Together, we'll explore all the amazing features of StyleTTS 2, and I'll share tips and tricks to get the most out of it. By the end of our journey, you'll feel like a pro at using this fantastic text-to-speech tool, ready to add that perfect, natural-sounding voice to your projects. Let's get started and have some fun with it!
What is StyleTTS2?
StyleTTS stands out in the world of text-to-speech technology due to its innovative integration of style diffusion and adversarial training alongside large speech language models (SLMs). This advanced approach enables StyleTTS to achieve a level of TTS synthesis that is remarkably close to natural human speech. The ability to blend nuanced vocal styles and intonations seamlessly makes StyleTTS 2 a game-changer in the industry. It's this cutting-edge sophistication that is rapidly garnering widespread recognition and acclaim for StyleTTS 2, making it one of the few best solution in the text-to-speech domain.
Here's an audio sample I've crafted using StyleTTS 2. This isn't just any ordinary text-to-speech output; it's a showcase of the remarkable advancements in speech synthesis technology.
If you are looking for are more in-depth tutorial on StyleTTS2 I strongly recommend you visit this our blog post.

How to use StyleTTS 2
One common hurdle that I've noticed many developers encounter is the initial phase of getting started with StyleTTS 2. This challenge is particularly pronounced for beginners in the field. StyleTTS 2, with its advanced features and capabilities, isn't the most straightforward tool to set up, especially if you're new to this kind of technology. I can personally attest to this, having experienced some of these challenges firsthand.
The complexity largely stems from the various dependencies and software requirements that are integral to running StyleTTS 2 effectively. For someone who isn't deeply versed in the technical aspects of speech synthesis software, navigating through this setup process can be quite daunting. It's a stark contrast to more user-friendly services like Unreal Speech and Eleven Labs, which are known for their ease of setup and user-friendly interfaces.
These simpler platforms often come with comprehensive guides and a more intuitive setup process, making them accessible even to those with minimal technical background. However, with StyleTTS 2, the learning curve is steeper. It demands a certain level of technical proficiency and understanding of speech synthesis frameworks, which can be a significant barrier for newcomers.
After conducting some research, I stumbled upon a much simpler method to utilize StyleTTS 2 without the hassle of manual setup. This solution involves using a service known as Replicate. What Replicate does is quite ingenious – it creates a user-friendly wrapper around various models, including StyleTTS 2, thereby offering an accessible and straightforward solution for developers eager to dive into using these models with minimal delay.
Replicate essentially streamlines the process, removing the technical complexities that often act as barriers for those new to this field or for developers looking for a quick start. It's designed with ease of use in mind, making it an ideal platform for anyone who wants to leverage the power of advanced models like StyleTTS 2 without getting bogged down in the intricacies of setup and configuration.
By using Replicate, developers can bypass the steep learning curve associated with setting up StyleTTS 2 from scratch. This service handles the underlying complexities, allowing you to focus more on the creative and practical applications of the tool rather than the technical setup. It's a game-changer for those who want to experiment with or implement advanced text-to-speech capabilities but have been deterred by the daunting setup process.
Get Started with StyleTTS2
Before diving into the world of StyleTTS 2, the very first step is to navigate to the Replicate website and set up an account. This is a crucial initial move, as having an account on Replicate is the gateway to accessing and utilizing the advanced capabilities of StyleTTS 2 with ease. Creating an account on Replicate is a straightforward process, designed to be user-friendly and accessible, ensuring that you can quickly move on to the exciting part of experimenting with StyleTTS 2. Once your account is active, you'll be well on your way to exploring the features of StyleTTS 2.
After creating your account the next thing we need to do is to click on the link below to open the StyleTTS 2 API on Replicate
The next we need to do is open our favorite code editor or IDE, I prefer Visual Studio Code because of it simplicity and rich features it offers. After opening our code editor the next thing to do is to create an API Key
To create an API Key click on your profile button and you would see a list of dropdown select API tokens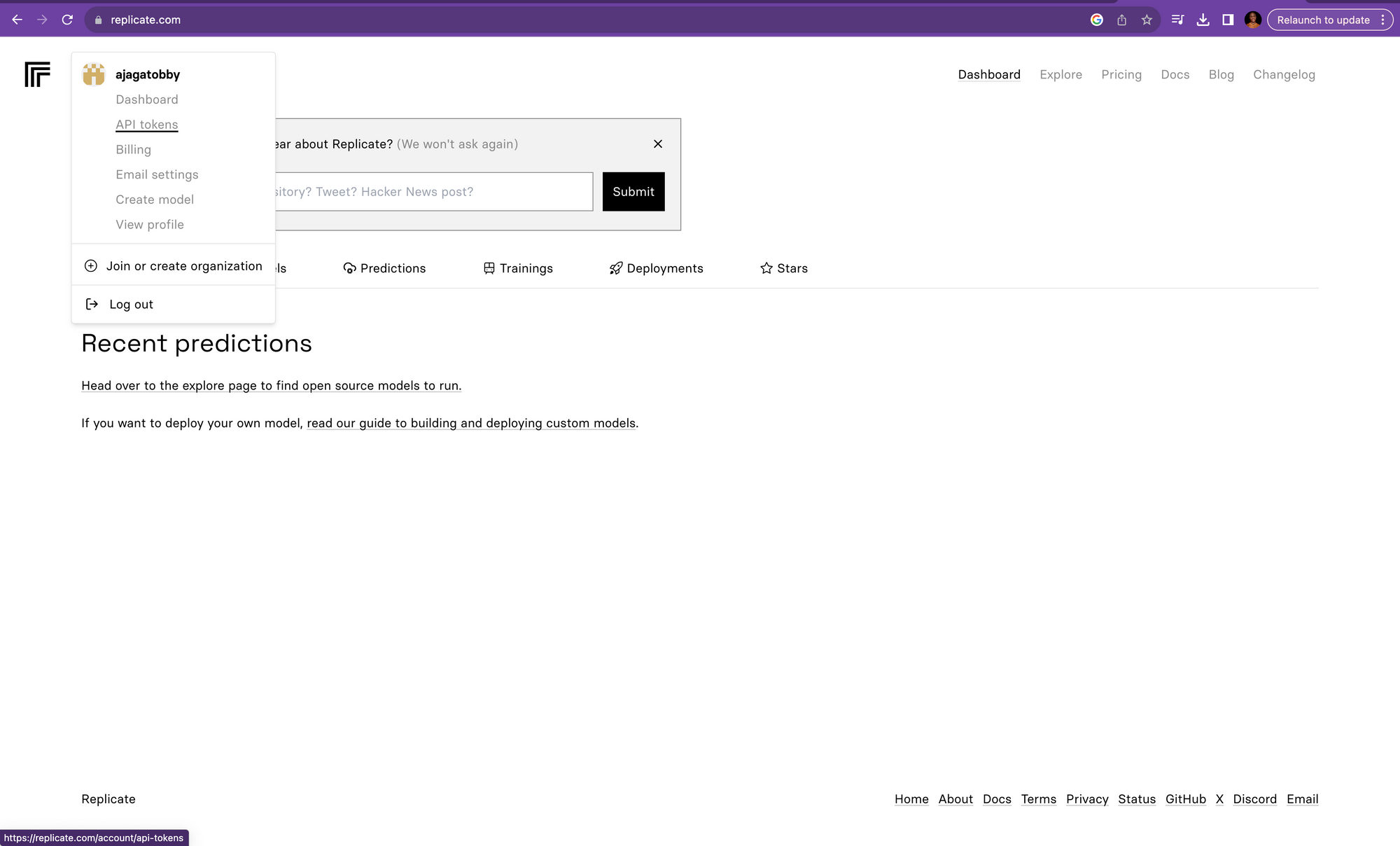
Once you select the option to create an API token on Replicate, you'll be directed to a new page specifically for this purpose. Here, you'll find a field where you can enter a name for your API token. This name is just a label to help you identify the token later, so choose something that makes sense to you. After naming your token, simply click on the Create button. This action will generate your new API token, a crucial piece of information that you'll use to interact with StyleTTS 2 through the Replicate platform.
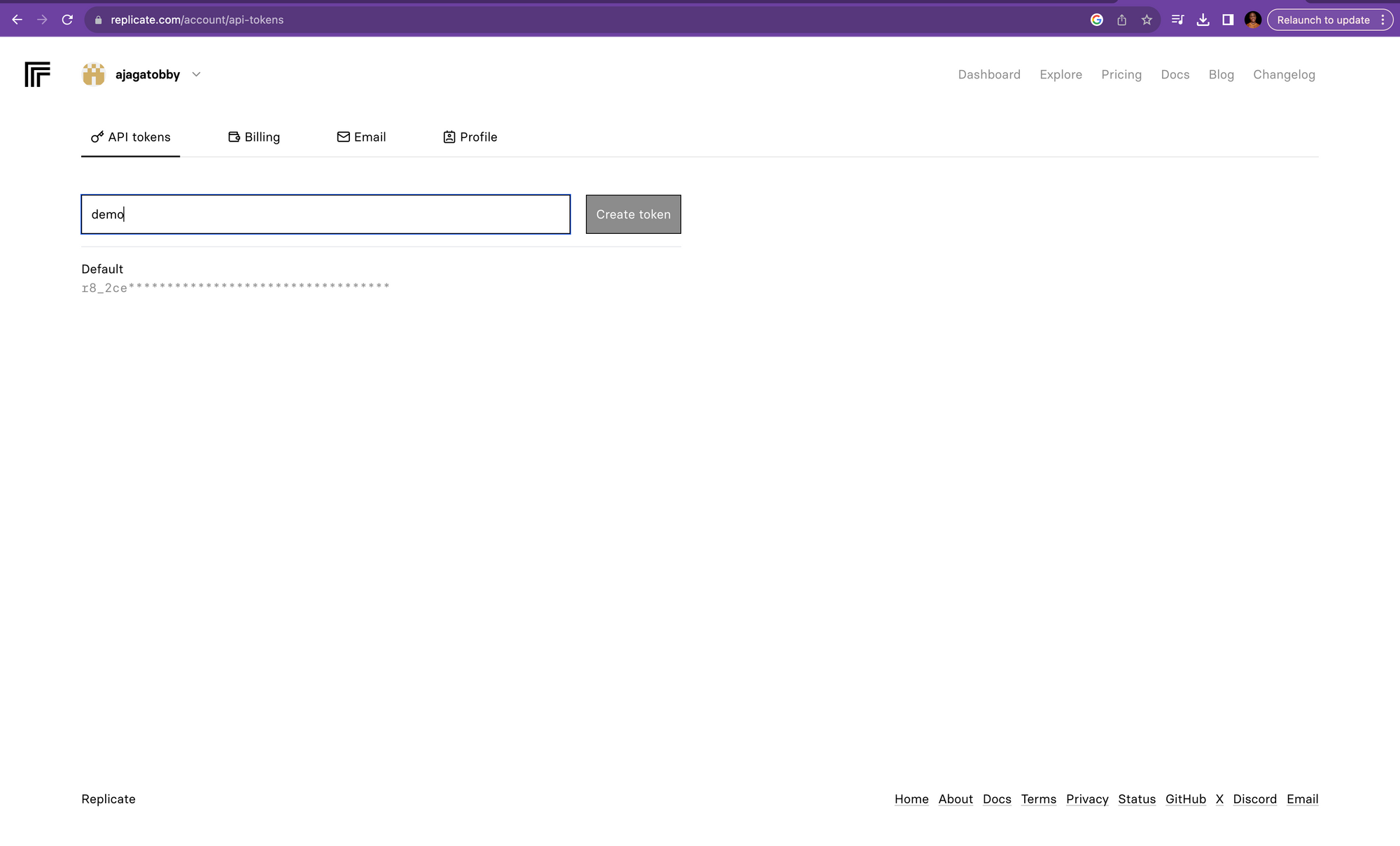
After coping the API Token the next step is to create .env file and paste the API Token you copied inside the .env file.
REPLICATE_API_TOKEN=YOUR_API_TOKEN
If you don't want to create .env file you could easily open your command and just paste the command below.
> export REPLICATE_API_TOKEN=YOUR_API_TOKEN
Having successfully set up our environment variables, we're now ready to move on to the next crucial step: installing the necessary dependencies for our project. These dependencies are essentially the building blocks that our application needs to function correctly and interact with StyleTTS 2 via Replicate.
Installing these dependencies is a key part of preparing our development environment. They might include libraries, frameworks, or other tools that are required to ensure smooth communication between our code and the StyleTTS 2 service. This step is vital because without these dependencies, our application might not be able to access the full range of functionalities offered by StyleTTS 2, or it might not run at all.
> pip install replicate
> pip install python-dotenv
Once you've installed all the necessary packages, the next step is to begin the actual coding process. Start by creating a file named main.py in your project directory. This file will serve as the central script where you'll write the code to interact with StyleTTS 2.
In main.py, you're going to write the code that harnesses the capabilities of StyleTTS 2 via Replicate. To get started, I'll provide you with a basic code snippet. This snippet is designed to give you a foundational structure, which you can then expand upon based on the specific requirements of your project.
Here's the code to copy and paste into your main.py file:
import replicate
from dotenv import load_dotenv
# Load environment variables
load_dotenv()
# Define the model identifier for StyleTTS 2
model_id = "adirik/styletts2:53fd5081feae9440974d1ef9cae83bf7af5fe18be1646343f37e559f5f80a613"
# Text to be synthesized
text_to_synthesize = "This is a demo to test for replicate voice generation"
# Running the StyleTTS 2 model
output = replicate.run(model_id, input={
"text": text_to_synthesize,
"beta": 0.7,
"seed": 0,
"alpha": 0.3,
"diffusion_steps": 10,
"embedding_scale": 1.5
})
# Output the result
print(output)
Output of our code, to run code all we need to do is to simply open our command and type python main.py this code would run our code.Inputs
To enhance clarity and understanding, let's reformat and elaborate on the input parameters for StyleTTS 2:
- Text (String): This is the primary input where you provide the text that you want to convert into speech. It's the script that the TTS engine will vocalize.
- Reference File: If you have a specific speech style in mind, you can use a reference audio file. The TTS engine will analyze this file and attempt to mimic the style and nuances of the speech in your text-to-speech output.
- Alpha (Number): This parameter is particularly useful for long text inputs or when using a reference speaker. It influences the timbre of the synthesized speech. Lower values mean the style will lean more towards the previous or reference speech rather than the text itself. The default value is 0.3. Adjusting this can help in fine-tuning the balance between the natural style of the text and the influence of the reference speech.
- Beta (Number): Similar to Alpha, but this parameter affects the prosody – the rhythm, stress, and intonation of speech. Again, lower values will cause the style to be more influenced by the previous or reference speech. The default value is 0.7. This is especially useful for ensuring the speech sounds natural and matches the desired flow and emphasis.
- Diffusion Steps (Integer): This determines the number of steps in the diffusion process. A higher number of steps can lead to more refined results but may increase processing time. The default value is 10.
- Embedding Scale (Number): This parameter controls the degree of emotion in the speech. Higher values result in more pronounced emotional expression. The default value is 1. This can be particularly useful for creating speech that conveys specific emotions or tones.
- Seed (Integer): This is used for reproducibility. If you want to generate the same speech output multiple times, using the same seed value will ensure consistency. The default value is 0.
Each of these parameters plays a crucial role in customizing the output of StyleTTS 2 to meet specific needs and preferences. By adjusting these inputs, you can significantly influence the quality, style, and emotional tone of the synthesized speech.
In conclusion
I trust that this guide has successfully demonstrated how to use Replicate to effortlessly operate StyleTTS2. If you're someone who finds visual learning more effective, I highly recommend watching the accompanying video. This visual aid is designed to complement the information in this blog post, offering a more dynamic and engaging way to grasp the concepts and steps involved.
The video provides a step-by-step walkthrough, visually illustrating each part of the process. From setting up your Replicate account to writing and executing the code in your IDE, the video makes these steps easy to follow and understand. It's an excellent resource for reinforcing what you've learned here and can be particularly helpful if you're new to using tools like StyleTTS2 and Replicate.
So, if you feel you'd benefit from a visual representation of the process, or if you simply want to reinforce your understanding, be sure to check out the video. It's tailored to ensure that you gain a comprehensive understanding of how to harness the power of StyleTTS2 with the simplicity and convenience of Replicate.