Text-to-Speech Evolution: The Impact of AI on Vocal Interactions

Envisioning Text-to-Speech: A Leap Beyond with AI and Neural Networks
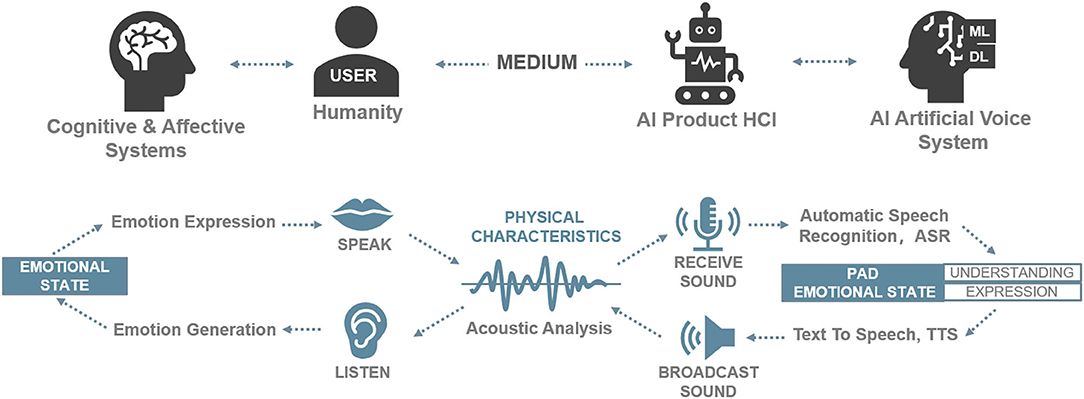
As we gaze into the current landscape and the impending future of Text-to-Speech technology, we stand at a pivotal juncture where AI and neural networks have begun to redefine the synthesis of speech, far surpassing previous capabilities. This evolution stems from an increased understanding of the intricate dynamics of vocal communication, paired with the computational prowess of machine learning models. American university researchers, alongside skilled software engineers, are provided with vocal replicas that are strikingly nuanced and expressive, all thanks to the leaps made within neural TTS tech. These advancements not only accentuate the potential for lifelike virtual assistants but also herald innovative avenues for user interaction within digital formats, thereby elevating the auditory component of technological interfaces to unprecedented heights.
The introduction of such sophisticated TTS applications is set to revolutionize educational tools, making learning more inclusive and immersive. Additionally, for engineers who integrate TTS into automated systems, the ability to include natural-sounding instructions and responses unlocks levels of practicality and user comfort that align closely with the conversational norms of society. The synergy of neural TTS tech with prolific programming languages like Python, Java, and Javascript opens up boundless opportunities for creative and tailored solutions, catering to a vast spectrum of use cases that range from accessibility to entertainment, reinforcing the transformative impact of neural capabilities in speech technology.
| Topics | Discussions |
|---|---|
| Overview of Emerging Trends in Text-to-Speech Technology | Insight into the latest developments in TTS technology, emphasizing the substantial role machine learning and neural networks play in enhancing speech quality. |
| Common Questions Re: TTS Technology | Frequently asked questions addressing key points about TTS capabilities, the role of AI in TTS, and its future direction. |
Overview of Emerging Trends in Text-to-Speech Technology
Within the realm of Text-to-Speech (TTS) development, technological lingua franca comprises a plethora of terms and concepts essential to understanding the field's advancements. As American academic researchers and seasoned software engineers delve into the complexities of TTS applications, familiarizing themselves with this terminology is critical. From neural networks that drive the fluidity of synthesized speech to algorithms that capture the subtleties of human intonation, this glossary serves as an essential resource in navigating the expansive universe of neural TTS tech.
Text-to-Speech (TTS): A technology that converts digital text into spoken word, typically using AI to simulate human speech.
Neural Networks: Computational models inspired by the human brain's neural structure, used to recognize patterns and generate speech in TTS systems.
Deep Learning: Advanced machine learning involving algorithms that mimic the processing of the human brain to interpret complex data.
Machine Learning (ML): The ability of machines to learn and adapt through algorithms and statistical models to perform specific tasks without explicit instructions.
AI (Artificial Intelligence): The simulation of human intelligence processes by machines, especially computer systems, integral to modern TTS.
Natural Language Processing (NLP): A subfield of linguistics and artificial intelligence that enables the understanding and manipulation of human language by software.
Voice Synthesis: The part of TTS dedicated to producing spoken language output that sounds like natural speech.
Speech Generation: The process within TTS technology that creates artificial speech through sound synthesis.
API (Application Programming Interface): An interface that allows for the integration of TTS capabilities into applications and services.
Customization: The process of tailoring TTS voice properties, like pitch or rate, to suit specific use cases or preferences.
TTS Implementation Guide
Integrating Basic TTS Functionality
Incorporating basic Text-to-Speech (TTS) functionality into your application generally starts by choosing a TTS service provider and registering for an API key. Below is a simplified workflow on how to use an example TTS API with Python:
import requests
response = requests.post(
'https://api.v6.unrealspeech.com/stream',
headers = {
'Authorization' : 'Bearer YOUR_API_KEY'
},
json = {
'Text': '''<YOUR_TEXT>''', # Up to 1,000 characters
'VoiceId': '<VOICE_ID>', # Scarlett, Dan, Liv, Will, Amy
'Bitrate': '192k', # 320k, 256k, 192k, ...
'Speed': '0', # -1.0 to 1.0
'Pitch': '1', # 0.5 to 1.5
'Codec': 'libmp3lame', # libmp3lame or pcm_mulaw
}
)
with open('audio.mp3', 'wb') as f:
f.write(response.content)Advanced TTS Features Integration
For more advanced features, such as choosing specific voice characters or modifying speech rate and pitch, the TTS API often offers additional parameters:
# Additional parameters for voice ID and speech rate adjustment. params = {'voice_id': 'VoiceCharacterId', 'rate': 1.2}
Include these parameters in the request body.
body.update(params)
Send the request as before.
response = requests.post(tts_endpoint, headers=headers, json=body)if response.status_code == 200:with open('output.mp3', 'wb') as audio_file:audio_file.write(response.content)
These examples provide a basic understanding of how to interact with a TTS API. Detailed documentation and support from the API provider are imperative for successful integration and exploitation of the full range of TTS capabilities.
Advantages of Unreal Speech's TTS API for Various Fields
Unreal Speech's TTS API offers substantial cost benefits by claiming to slash text-to-speech development costs by up to 90%, providing an affordable solution that stands up to ten times cheaper than services such as Eleven Labs and Play.ht, and up to twice as affordable as those offered by tech giants like Amazon, Microsoft, and Google. For academic researchers, this cost efficiency means extending budgets further while accessing high-quality TTS technology for their studies, be it in linguistics, cognitive science, or AI.
Software engineers are poised to benefit from Unreal Speech's competitive pricing and high-volume handling, enabling them to integrate TTS functionality into large-scale projects without prohibitive costs. With features like low-latency responses and an estimated uptime of 99.9%, Unreal Speech presents a reliable TTS service that can support the demanding requirements of software development, such as real-time applications, with ease and financial prudence.
For game developers aiming to create immersive experiences, Unreal Speech's diversified array of voices, from various speaking styles to emotional tones, offers a creative palette to enhance storytelling and character development. Educators, too, can leverage the TTS API to make learning content more accessible and engaging, providing students with diverse auditory learning options. The promise of multilingual support expands educational opportunities across language barriers and broadens the reach of content creation.
Common Questions Re: TTS Technology
Understanding Neural TTS Implementation
Neural Text-to-Speech (TTS) utilizes deep learning technology to generate speech that closely mimics the nuances and intricacies of human speech. This advanced implementation of TTS leverages neural networks that have been trained on vast amounts of speech data, enabling the synthesis of voices that are rich, dynamic, and contextually appropriate for various communicative requirements.
Comprehending Neural vs. Standard TTS
Neural TTS differs from standard TTS in its foundational approach to voice generation. Standard TTS technologies typically piece together small clips of recorded speech to create sentences, which can result in less fluid and robotic sounding output. Neural TTS, conversely, is based on models that predict and generate speech waveforms from scratch, resulting in smoother and more natural articulation throughout.
Exploring TTS in Modern Technology
The incorporation of TTS into modern technology has opened up a myriad of interactive applications. TTS enhances user experiences in automotive navigation systems, virtual assistants across smart devices, accessibility tools for those with visual impairments, language learning apps that provide pronunciation practice, and many other scenarios where spoken output is advantageous or necessary.