Unlocking TTS Synthesis: A Deep Dive into Machine Learning's Role - Explore Best AI Voice Generators

The Evolution of Text-to-Speech: Exploring Machine Learning's Role in TTS Synthesis
The advent of machine learning has ushered in a new era for TTS technology, one where artificial voices are increasingly indistinguishable from human speakers. This evolution is predicated on breakthroughs in neural networks and data-driven learning, allowing for significant leaps in naturalness, fluidity, and expressiveness of synthesized speech. The crux of modern TTS lies in its ability to adapt to varying text inputs and contexts, outputting speech that aligns with human intonation patterns and emotional cues, qualities that the best AI voice generators strive to perfect.
For developers and researchers immersed in creating refined TTS solutions, the progress in the field is marked by key benchmarks such as LJSpeech and CMUDict, and the comprehensive datasets that serve to train and evaluate these sophisticated systems. Whether the aim is to integrate TTS functionality into free text to speech software for PC, or to harness the capabilities of advanced text to speech synthesis online free platforms, understanding and leveraging these datasets plays a crucial role in advancing both the science and practical applications of TTS synthesis.
| Topics | Discussions |
|---|---|
| State-of-the-Art Text-to-Speech | Discover the cutting-edge technologies and models that exemplify the latest developments in TTS, elevating voice synthesis to new levels of naturalness and precision. |
| Benchmarking TTS Advancements | Explore the benchmarks that are used to measure the performance of speech synthesis software, reflecting the progression and quality of the best AI voice generators. |
| Technical Quickstart: Implementing TTS with Code Examples | Technical tutorials and programming code examples that provide a practical starting point for developers keen on TTS development in Python, Java, and JavaScript. |
| Navigating TTS Resources | A guide through the valuable resources available for TTS synthesis, from free text to speech software for PC to comprehensive state-of-the-art datasets and methods. |
| Common Questions Re: TTS Basics and Developments | Answers to the most common questions related to TTS, clarifying how text to speech synthesis works, examples of TTS in action, and the nuances between speech synthesis and TTS. |
State-of-the-Art Text-to-Speech
As we delve into the realm of TTS, it's pivotal to familiarize oneself with the jargon that often colors technical discussions and literature. From neural networks that form the backbone of machine learning to datasets that nourish these advanced algorithms, the intricate details of TTS can be better appreciated through the lexicon of its technology. Let's break down these terms into a digestible glossary that will enhance your understanding of the state-of-the-art developments in speech synthesis software.
| Term | Definition |
|---|---|
| Text-to-Speech (TTS) | A technology that converts written text into audible speech, mimicking human-like enunciation and tonality. |
| Machine Learning | A subset of artificial intelligence that enables software to improve automatically through experience and data. |
| Neural Networks | Computational models inspired by the human brain's network of neurons, essential for complex tasks like TTS. |
| Deep Learning | An advanced type of machine learning involving neural networks with many layers, capable of interpreting data with a high level of abstraction. |
| Benchmarks | Standardized tests used to evaluate and compare the performance of TTS models against one another. |
| Training Data | Datasets specifically designed for training machine learning models to recognize and process patterns. |
| NaturalSpeech | A leading model known for generating high-quality, natural-sounding speech in TTS applications. |
| Token-Level Ensemble Distillation | A machine learning technique used to enhance the clarity and naturalness of synthesized speech. |
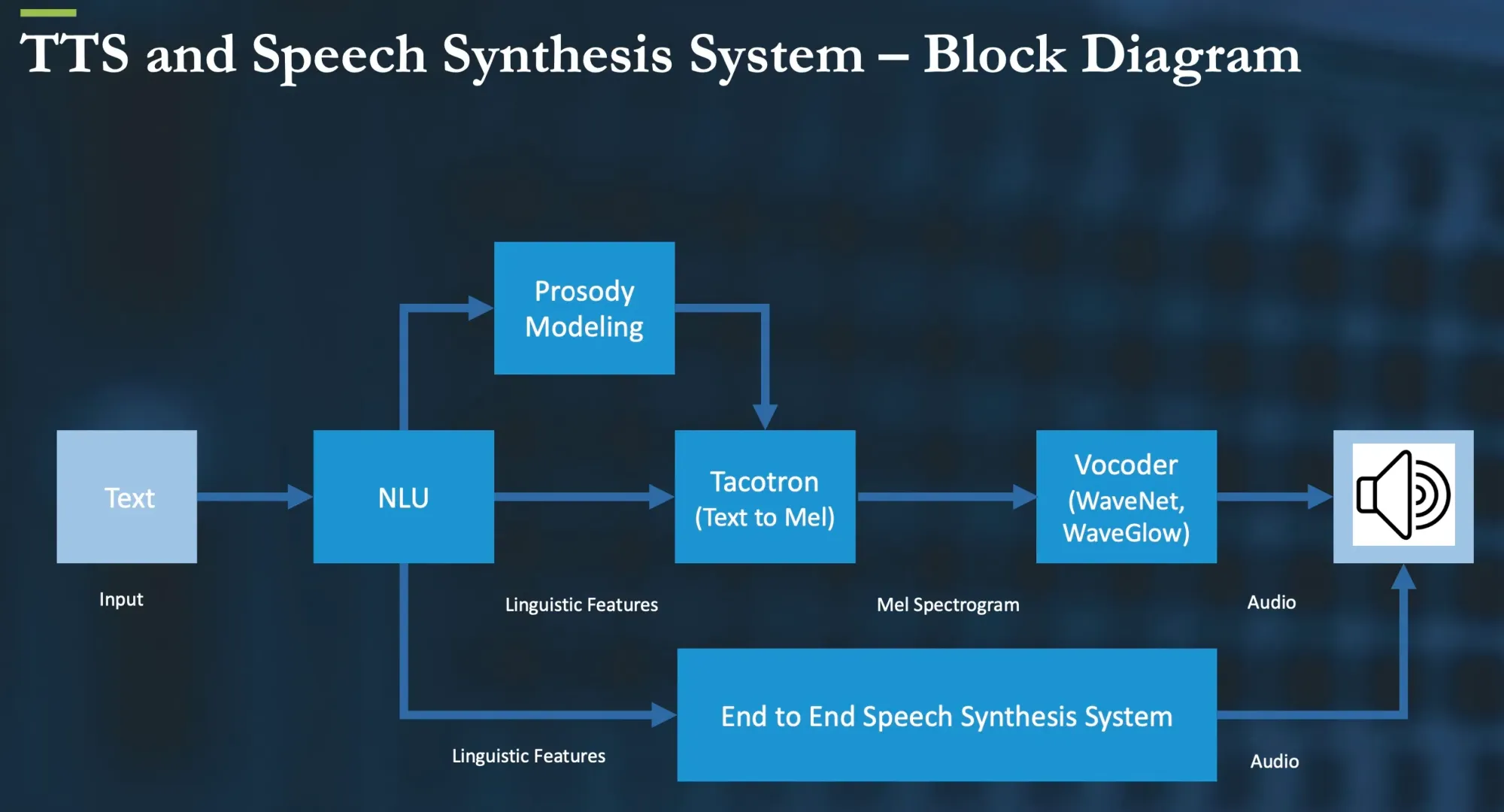
Benchmarking TTS Advancements
Benchmarking is a critical process in the field of TTS that allows researchers and developers to gauge how well their systems are performing in relation to established standards and peer solutions. Different benchmarks serve distinct purposes; for instance, some might measure the naturalness and intelligibility of speech, while others might focus on the ability to handle different languages or dialects. By stressing the importance of these benchmarks, the TTS community stays focused on targeting the key areas for improvement, thus driving innovation forward.
In particular, benchmarks like LJSpeech, CMUDict 0.7b, and corpora of 20000 utterances are not just testing grounds but also repositories of data that serve as training material for state-of-the-art models. These models, such as NaturalSpeech and those employing Token-Level Ensemble Distillation, are then able to push the envelope, achieving more human-like speech synthesis. These advancements not only make the technology more usable in practical applications but also contribute to the overarching quest for creating TTS that can fully emulate the subtleties of human communication.
The strides made through these benchmarks reflect a concerted effort in the TTS community to continuously challenge the status quo, staying at the cutting edge of what's possible in AI-driven speech synthesis. With each new iteration and subsequent evaluation through these benchmarks, TTS moves closer to achieving a seamless integration into everyday interactions, redefining how we engage with technology using the power of voice.
Technical Quickstart: Implementing TTS with Code Examples
Python Programming for Text to Speech Synthesis
from gtts import gTTS
This code snippet generates an MP3 file with the spoken version of the string passed to gTTS. In just a few lines of code, you can have a basic TTS system up and running.
Java and JavaScript Approaches to Voice Generation
While Java has been a long-standing option for backend development, JavaScript, with its extensive ecosystem and the power of Node.js, has become a popular choice for implementing TTS, especially in web applications. If you're working on a web application, the Web Speech API provides an easy entry point:
const axios = require('axios');
const fs = require('fs');
const headers = {
'Authorization': 'Bearer YOUR_API_KEY',
};
const data = {
'Text': '<YOUR_TEXT>', // Up to 1,000 characters
'VoiceId': '<VOICE_ID>', // Scarlett, Dan, Liv, Will, Amy
'Bitrate': '192k', // 320k, 256k, 192k, ...
'Speed': '0', // -1.0 to 1.0
'Pitch': '1', // 0.5 to 1.5
'Codec': 'libmp3lame', // libmp3lame or pcm_mulaw
};
axios({
method: 'post',
url: 'https://api.v6.unrealspeech.com/stream',
headers: headers,
data: data,
responseType: 'stream'
}).then(function (response) {
response.data.pipe(fs.createWriteStream('audio.mp3'))
});This JavaScript code uses the SpeechSynthesisUtterance interface to turn text into speech right in the browser, offering a quick way to add voice features to your web application without the need for backend processing.
Navigating TTS Resources
In the competitive landscape of TTS APIs, Unreal Speech emerges as a cost-effective and efficient solution that promises to revolutionize the space. With claims of slashing TTS costs by up to 90% and being significantly cheaper than well-known providers like Eleven Labs, Play.ht, Amazon, Microsoft, and Google, Unreal Speech stands out for those who need to incorporate high-quality TTS into their services without incurring exorbitant costs. Its payment structure is tiered and usage-based, rewarding higher usage with lower costs which could especially benefit enterprises with large-scale TTS needs.
For academic researchers who are often limited by stringent budgets, Unreal Speech offers a way to integrate TTS into their projects at a fraction of the standard cost. Software engineers working on developing applications with TTS features can take advantage of Unreal Speech's API for rapid development, thanks to its simple integration and robust documentation. Game developers can use it to bring characters to life with natural speech, and educators can incorporate it into learning materials to make content more accessible.
Unreal Speech not only promises a reduction in TTS costs but also boasts impressive performance with low latency and high uptime, ensuring that users can rely on the service for critical real-time applications. Their enterprise plan includes a significant monthly character allowance with over 14,000 hours of audio duration, catering to those with extensive audio generation needs. Furthermore, the addition of per-word timestamps enhances the quality of speech synchronization, beneficial for creating detailed and immersive audio experiences in various applications.
Common Questions Re: TTS Basics and Developments
Exploring the Fundamentals: How Does TTS Synthesis Work?
TTS synthesis refers to the technology that enables the conversion of written text into spoken words using artificial intelligence and machine learning. It involves intricate processes that analyze the text's linguistic properties and generate corresponding speech sounds.
Diving Deeper: Can You Illustrate a TTS Synthesizer in Action?
A TTS synthesizer creates audible speech from text, often used in applications such as virtual assistants or reading apps. For example, entering text into a TTS software produces a voice output that reads the input text aloud.
Distinguishing the Techniques: How Do Speech Synthesis and TTS Differ?
Speech synthesis generally encompasses all methods of generating spoken language artificially. TTS is a subset of speech synthesis focused specifically on transforming text into speech, often through the use of digital processing methods and AI.