Enhancing English Automatic Speech Recognition with Wav2Vec2 Using Hugging Face Transformers 🤗
Introduction
Wav2Vec2, a groundbreaking pretrained model specifically designed for Automatic Speech Recognition (ASR), was introduced in September 2020 by a team of researchers including Alexei Baevski, Michael Auli, and Alex Conneau. This innovative model represents a significant advancement in the field of speech recognition technology.
At the core of Wav2Vec2's methodology is a unique contrastive pretraining objective, a technique that enables the model to learn rich and effective speech representations. This is achieved by processing an extensive corpus of over 50,000 hours of unlabeled speech data. The diversity and volume of this data play a crucial role in enhancing the model's ability to understand and interpret various speech patterns and accents.
Drawing inspiration from BERT’s approach to natural language understanding, Wav2Vec2 employs a similar strategy known as masked language modeling. However, instead of processing text, Wav2Vec2 applies this technique to audio data. The process involves randomly masking some of the feature vectors in the audio input. These masked vectors are then fed into a transformer network, a powerful type of neural network architecture renowned for its efficiency in handling sequential data.
The transformer network within Wav2Vec2 is tasked with predicting the masked audio features. Through this exercise, the model learns to understand the context and nuances of speech, thereby developing contextualized speech representations. This approach enables Wav2Vec2 to capture the subtleties and complexities of spoken language, ranging from different accents and dialects to variations in speech due to emotional states or environmental factors.
As a result, Wav2Vec2 is not just capable of transcribing speech accurately but also of understanding it in a way that is more akin to human perception. This makes it an invaluable tool for a wide array of applications in the field of ASR, from voice-activated assistants to automated transcription services, offering enhanced accuracy and efficiency over previous models.
In this notebook, we'll provide a comprehensive explanation of how to fine-tune Wav2Vec2's pretrained checkpoints on any English ASR dataset. We'll cover all the necessary steps and provide detailed guidance. In this notebook, we'll explore the process of fine-tuning Wav2Vec2 without relying on a language model. Using Wav2Vec2 without a language model as an end-to-end ASR system is a breeze. In fact, studies have demonstrated that the standalone Wav2Vec2 acoustic model delivers remarkable results. In this example, we'll be showcasing how we take the pretrained checkpoint of the "base" size and fine-tune it on the Timit dataset, which is relatively small with only 5 hours of training data.
Wav2Vec2 is fine-tuned using Connectionist Temporal Classification (CTC), an algorithm commonly employed to train neural networks for sequence-to-sequence problems. It finds extensive application in fields such as Automatic Speech Recognition and handwriting recognition.
I highly recommend checking out the blog post "Sequence Modeling with CTC (2017)" by Awni Hannun. It's a really well-written piece that you don't want to miss!
First things first, let's make sure we have both datasets and transformers installed from the master branch. In order to load audio files and evaluate our fine-tuned model using the word error rate (WER) metric, we'll need to make sure we have the soundfile package and jiwer installed.
!pip install datasets>=1.18.3
!pip install transformers==4.11.3
!pip install librosa
!pip install jiwer
Next I strongly suggest to upload your training checkpoints directly to the Hugging Face Hub while training. The Hub has integrated version control so you can be sure that no model checkpoint is getting lost during training.
To do so you have to store your authentication token from the Hugging Face website (sign up here if you haven't already!)
from huggingface_hub import notebook_login
notebook_login()
Print Output:
Login successful
Your token has been saved to /root/.huggingface/token
Authenticated through git-crendential store but this isn't the helper defined on your machine.
You will have to re-authenticate when pushing to the Hugging Face Hub. Run the following command in your terminal to set it as the default
git config --global credential.helper store
Then you need to install Git-LFS to upload your model checkpoints:
!apt install git-lfs
Timit is usually evaluated using the phoneme error rate (PER), but by far the most common metric in ASR is the word error rate (WER). To keep this notebook as general as possible we decided to evaluate the model using WER.
Prepare Data, Tokenizer, Feature Extractor
ASR models transcribe speech to text, which means that we both need a feature extractor that processes the speech signal to the model's input format, e.g. a feature vector, and a tokenizer that processes the model's output format to text.
In 🤗 Transformers, the Wav2Vec2 model is thus accompanied by both a tokenizer, called Wav2Vec2CTCTokenizer, and a feature extractor, called Wav2Vec2FeatureExtractor.
Let's start by creating the tokenizer responsible for decoding the model's predictions.
Create Wav2Vec2CTCTokenizer
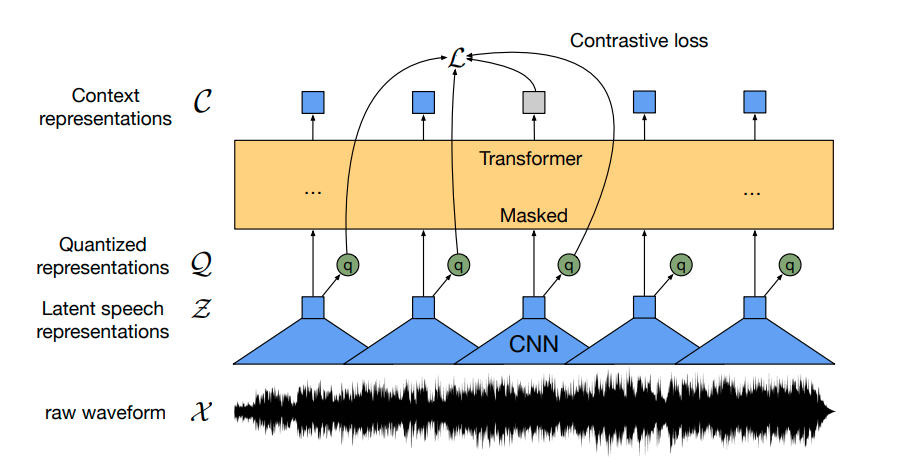
The pretrained Wav2Vec2 checkpoint maps the speech signal to a sequence of context representations as illustrated in the figure above. A fine-tuned Wav2Vec2 checkpoint needs to map this sequence of context representations to its corresponding transcription so that a linear layer has to be added on top of the transformer block (shown in yellow). This linear layer is used to classifies each context representation to a token class analogous how, e.g., after pretraining a linear layer is added on top of BERT's embeddings for further classification - cf.
The output size of this layer corresponds to the number of tokens in the vocabulary, which does not depend on Wav2Vec2's pretraining task, but only on the labeled dataset used for fine-tuning. So in the first step, we will take a look at Timit and define a vocabulary based on the dataset's transcriptions.
Let's start by loading the dataset and taking a look at its structure.
from datasets import load_dataset, load_metric
timit = load_dataset("timit_asr")
print(timit)
Print Output:
DatasetDict({
train: Dataset({
features: ['file', 'audio', 'text', 'phonetic_detail', 'word_detail', 'dialect_region', 'sentence_type', 'speaker_id', 'id'],
num_rows: 4620
})
test: Dataset({
features: ['file', 'audio', 'text', 'phonetic_detail', 'word_detail', 'dialect_region', 'sentence_type', 'speaker_id', 'id'],
num_rows: 1680
})
})
It's quite common for ASR datasets to only include the target text, 'text', for each audio file, 'file'. Timit offers a wealth of additional information for each audio file, including the 'phonetic_detail' and more. This is why many researchers prefer to assess their models based on phoneme classification rather than speech recognition when using Timit. But let's make sure the notebook stays as general as possible, focusing only on the transcribed text for fine-tuning.
timit = timit.remove_columns(["phonetic_detail", "word_detail", "dialect_region", "id", "sentence_type", "speaker_id"])
Now, we can create a simple function to showcase a few random samples from the dataset. By running this function multiple times, we can gain a better understanding of the transcriptions.
from datasets import ClassLabel
import random
import pandas as pd
from IPython.display import display, HTML
def show_random_elements(dataset, num_examples=10):
assert num_examples <= len(dataset), "Can't pick more elements than there are in the dataset."
picks = []
for _ in range(num_examples):
pick = random.randint(0, len(dataset)-1)
while pick in picks:
pick = random.randint(0, len(dataset)-1)
picks.append(pick)
df = pd.DataFrame(dataset[picks])
display(HTML(df.to_html()))
show_random_elements(timit["train"].remove_columns(["file", "audio"]))
Idx Transcription
1 Who took the kayak down the bayou?
2 As such it acts as an anchor for the people.
3 She had your dark suit in greasy wash water all year.
4 We're not drunkards, she said.
5 The most recent geological survey found seismic activity.
6 Alimony harms a divorced man's wealth.
7 Our entire economy will have a terrific uplift.
8 Don't ask me to carry an oily rag like that.
9 The gorgeous butterfly ate a lot of nectar.
10 Where're you takin' me?
Sure thing! I must say, the transcriptions are impressively polished and the language used gives off a more formal written vibe rather than casual conversation. It's worth noting that Timit is a read speech corpus, which adds to its credibility.
It's interesting to note that the transcriptions include a variety of special characters like commas, periods, question marks, exclamation points, semicolons, and colons. Classifying speech chunks becomes more challenging without a language model, as they don't align with distinct sound units. For example, the letter "s" has a distinct sound, while the special character "." doesn't quite have the same clarity. In order to fully grasp the meaning of a speech signal, there is typically no need to incorporate any special characters into the transcription.
Moreover, we ensure that the text is converted to lowercase letters.
import re
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"]'
def remove_special_characters(batch):
batch["text"] = re.sub(chars_to_ignore_regex, '', batch["text"]).lower()
return batch
timit = timit.map(remove_special_characters)
Let's take a look at the preprocessed transcriptions.
show_random_elements(timit["train"].remove_columns(["file", "audio"]))
Print Output:
Idx Transcription
1 anyhow it was high time the boy was salted
2 their basis seems deeper than mere authority
3 only the best players enjoy popularity
4 tornados often destroy acres of farm land
5 where're you takin' me
6 soak up local color
7 satellites sputniks rockets balloons what next
8 i gave them several choices and let them set the priorities
9 reading in poor light gives you eyestrain
10 that dog chases cats mercilessly
Great! I must say, this is quite an improvement. We've taken out most of the special characters from the transcriptions and made sure they're all in lowercase.
Just like many bloggers do, it's typical to categorize speech chunks into letters, so we'll follow suit in this case. So, here's the plan: we're going to take all the unique letters from both the training and test data and use them to create our very own vocabulary.
In this mapping function, we'll combine all the transcriptions into a single long transcription and then convert the string into a set of characters. Passing the argument batched=True to the map(...) function is crucial in order to ensure that the mapping function can access all transcriptions simultaneously.
def extract_all_chars(batch):
all_text = " ".join(batch["text"])
vocab = list(set(all_text))
return {"vocab": [vocab], "all_text": [all_text]}
vocabs = timit.map(extract_all_chars, batched=True, batch_size=-1, keep_in_memory=True, remove_columns=timit.column_names["train"])
Now, we create the union of all distinct letters in the training dataset and test dataset and convert the resulting list into an enumerated dictionary.
vocab_list = list(set(vocabs["train"]["vocab"][0]) | set(vocabs["test"]["vocab"][0]))
vocab_dict = {v: k for k, v in enumerate(vocab_list)}
vocab_dict
Print Output:
{
' ': 21,
"'": 13,
'a': 24,
'b': 17,
'c': 25,
'd': 2,
'e': 9,
'f': 14,
'g': 22,
'h': 8,
'i': 4,
'j': 18,
'k': 5,
'l': 16,
'm': 6,
'n': 7,
'o': 10,
'p': 19,
'q': 3,
'r': 20,
's': 11,
't': 0,
'u': 26,
'v': 27,
'w': 1,
'x': 23,
'y': 15,
'z': 12
}
It's pretty cool to see that all the letters of the alphabet are present in the dataset, which is not really surprising. We also managed to extract the special characters " " and '. It's important to note that we didn't exclude those special characters for a specific reason:
In order for the model to accurately predict when a word ends, it is crucial to avoid generating a continuous string of characters. This is essential for effectively separating words from one another.
When it comes to English, it's important to remember that the ' character plays a crucial role in distinguishing between words. For instance, "it's" and "its" may seem similar, but they carry distinct meanings.
In order to emphasize the fact that " " has its own token class, we have decided to represent it with a more prominent character, namely |. Furthermore, we include a "unknown" token to ensure that the model can effectively handle characters that were not present in Timit's training set.
vocab_dict["|"] = vocab_dict[" "]
del vocab_dict[" "]
Print Output:
30
Cool, now our vocabulary is complete and consists of 30 tokens, which means that the linear layer that we will add on top of the pretrained Wav2Vec2 checkpoint will have an output dimension of 30.
Let's now save the vocabulary as a json file.
import json
with open('vocab.json', 'w') as vocab_file:
json.dump(vocab_dict, vocab_file)
In a final step, we use the json file to instantiate an object of the Wav2Vec2CTCTokenizer class.
from transformers import Wav2Vec2CTCTokenizer
tokenizer = Wav2Vec2CTCTokenizer("./vocab.json", unk_token="[UNK]", pad_token="[PAD]", word_delimiter_token="|")
If one wants to re-use the just created tokenizer with the fine-tuned model of this notebook, it is strongly advised to upload the tokenizer to the 🤗 Hub. Let's call the repo to which we will upload the files "wav2vec2-large-xlsr-turkish-demo-colab":
repo_name = "wav2vec2-base-timit-demo-colab"
and upload the tokenizer to the 🤗 Hub.
tokenizer.push_to_hub(repo_name)
Great, you can see the just created repository under https://huggingface.co/<your-username>/wav2vec2-base-timit-demo-colab
Features
The features of the Wav2Vec2 model for Automatic Speech Recognition (ASR) are quite impressive and innovative, contributing significantly to its performance and effectiveness. Here's a detailed look at some of its key features:
- Contrastive Pretraining Objective: Wav2Vec2 employs a contrastive pretraining approach, which is a novel method in the realm of speech recognition. This technique involves learning from a large dataset of unlabeled speech, allowing the model to understand a wide range of speech patterns without the need for annotated data.
- Large Unlabeled Dataset: The model is trained on over 50,000 hours of unlabeled speech. This extensive dataset encompasses a variety of languages, accents, and speaking styles, providing a rich and diverse training environment that contributes to the model's robustness and versatility.
- Masked Feature Learning: Similar to BERT’s approach in natural language processing, Wav2Vec2 uses a masked language model but applies it to audio features. This involves masking some of the audio input and then predicting these masked portions. This process helps the model to learn contextualized speech representations.
- Transformer Network: At the heart of Wav2Vec2 lies a transformer network. Transformers are known for their effectiveness in processing sequential data, and they play a crucial role in enabling the model to handle the sequential nature of speech.
- Contextualized Speech Representations: By predicting masked audio features, Wav2Vec2 learns contextualized representations of speech. This means it can understand speech in context, improving its ability to deal with homophones, accents, and various speaking styles.
- Robustness to Variability in Speech: Thanks to its extensive training on diverse datasets, Wav2Vec2 is robust against various challenges in speech recognition such as background noise, different accents, and speech impediments.
- Adaptability to Multiple Languages: Although primarily designed for English, Wav2Vec2's training approach makes it adaptable to other languages. This adaptability is crucial for developing multilingual ASR systems.
- Efficiency in Learning: The model's ability to learn from unlabeled data reduces the dependence on costly and time-consuming labeled datasets, making the process of developing and refining ASR systems more efficient.
- Fine-Tuning Capabilities: Wav2Vec2 can be fine-tuned with a smaller amount of labeled data for specific tasks or domains. This fine-tuning enhances its accuracy and efficiency for specialized applications.
- State-of-the-Art Performance: Wav2Vec2 has demonstrated state-of-the-art performance in various ASR benchmarks, outperforming many existing models in accuracy and speed.
These features make Wav2Vec2 a highly advanced and effective tool for ASR, suitable for a wide range of applications from voice-activated systems to automated transcription services, and contributing to advancements in the field of speech technology.
Conclusion
In conclusion, the Wav2Vec2 model represents a significant leap forward in the field of Automatic Speech Recognition (ASR). Its innovative features not only showcase the advancements in neural network design and training methodologies but also mark a substantial improvement in how machines process and understand human speech.
The use of a contrastive pretraining objective, inspired by techniques in natural language processing, has been a game-changer. By learning from a vast corpus of over 50,000 hours of unlabeled speech, Wav2Vec2 has achieved a remarkable level of understanding of various speech patterns, accents, and nuances. This extensive exposure to diverse speech data has equipped the model with an unprecedented ability to recognize and interpret spoken language in a contextually rich manner.
The implementation of a transformer-based architecture in Wav2Vec2 further underscores its sophistication. Transformers, known for their efficiency in handling sequential data, have enabled the model to process speech with a high degree of accuracy and speed. The ability of Wav2Vec2 to learn contextualized speech representations through its masked feature learning approach mirrors human speech processing more closely than ever before.
Moreover, Wav2Vec2's robustness to variability in speech, including different accents, background noises, and speaking styles, sets a new standard for ASR systems. This robustness, combined with the model's adaptability to multiple languages, opens up possibilities for creating more inclusive and versatile speech recognition applications worldwide.
The efficiency of Wav2Vec2 in learning from unlabeled data also represents a significant stride in making speech recognition technology more accessible and less reliant on resource-intensive labeled datasets. Furthermore, the model's fine-tuning capabilities ensure that it can be adapted for specific tasks and domains, enhancing its practicality and applicability in various specialized fields.
Wav2Vec2's state-of-the-art performance in various ASR benchmarks is a testament to its effectiveness and the potential it holds for the future of speech technology. From developing more responsive voice-activated assistants to creating more accurate and efficient automated transcription services, the implications of Wav2Vec2's capabilities are far-reaching.
In summary, Wav2Vec2 is not just a technological achievement in the realm of ASR; it is a beacon that guides the future direction of speech recognition technology. Its development marks a significant milestone in our journey towards creating machines that can understand and interact with human speech as naturally and effectively as we do.